前言
前文对kafka进行了一些粗略的介绍,相信大家对MQ届的老牌明星是有了一定了解的,本文将对MQ届的闪耀新星Apache Pulsar进行介绍,分为上(原理篇)下(实践篇)两个篇章。准备好了就开冲~
Pulsar的整体架构
基础架构
Apache Pulsar 当然也是一款MQ,它是Pub/Sub型的消息系统,但是从架构设计上来说与前文介绍的kafka是完全不同的,Pulsar在结构上将计算与存储完全分离。先看下图来初步认识下Pulsar的整体架构:
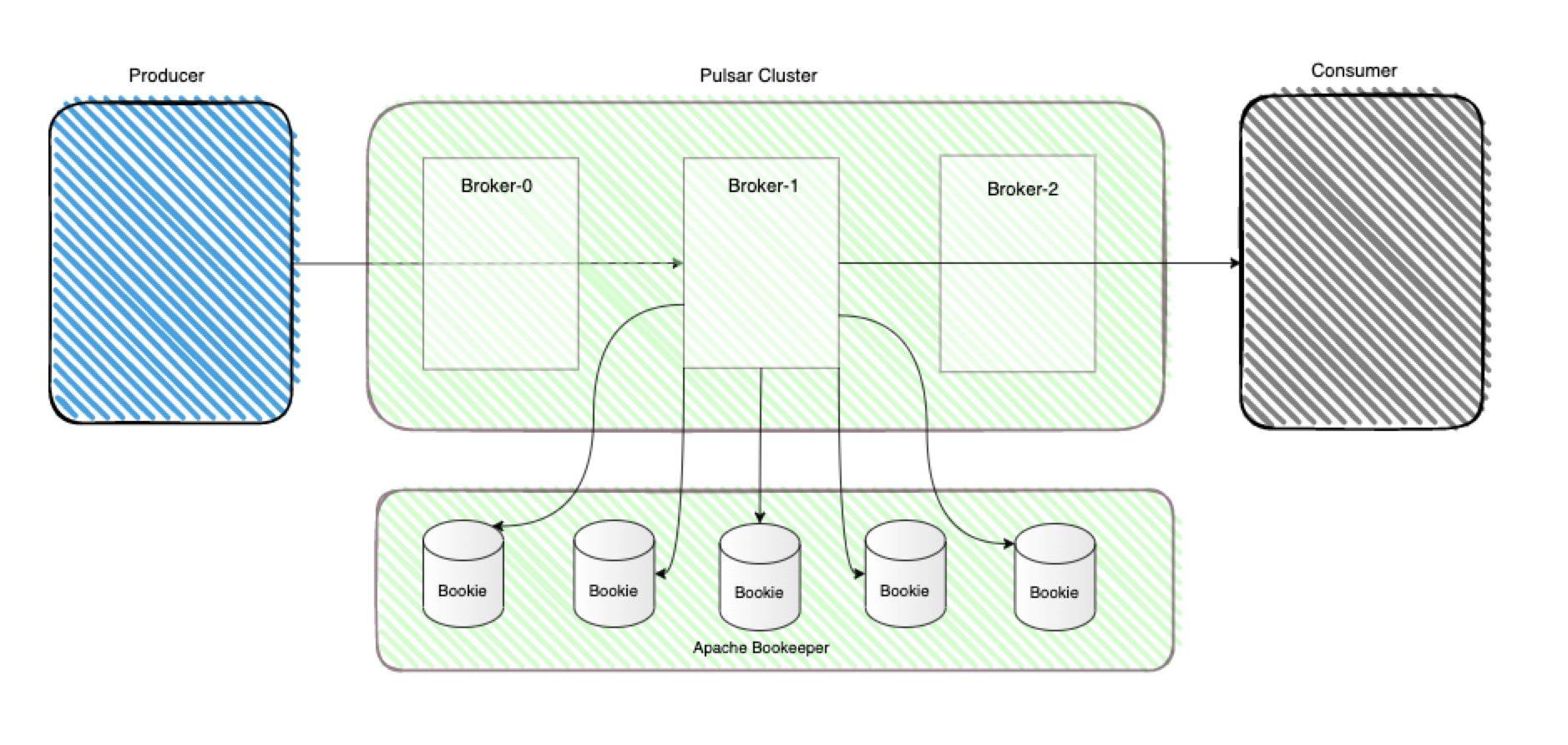
计算与存储的分离
对上图中的名词来一一解释一下
Apache Pulsar 主要包括 Broker, Apache BookKeeper, Producer, Consumer等核心组件。
- Broker:无状态(stateless)服务层,只负责接收和传递消息、集群负载均衡等工作,Broker 不存储任何元数据信息转由zookeeper存储元数据信息,因此可以快速的上、下线;
- Apache BookKeeper:有状态(stateful)持久层,由一组名为 Bookie 的存储节点组成,Broker层接收到的消息持久化于此处;
- Producer : 消息生产者,负责生产消息到Broker 的 Topic;
- Consumer:消息消费者,负责从 Topic 订阅数据,这里值得注意的一点是:Pulsar是push模式;
除了上述的组件之外,Apache Pulsar 还依赖 Zookeeper 作为元数据存储。与传统的消息队列(Kafka)相比,Apache Pulsar 在架构设计上采用了计算与存储分离的模式,Pub/Sub 相关的计算逻辑在 无状态的Broker 上完成,数据存储在 Apache BookKeeper 的 Bookie 节点上。
具体如何存储
讲了这么多,那Apache Pulsar在存储上面具体是怎样设计的了?来看下图, 在存储设计上Pulsar也不同于传统 MQ 的分区数据本地存储的模式,采用的是逻辑分区物理分片存储的模式,存储粒度比分区更细化、存储负载更均衡。 Apache Pulsar 中的每个 Topic 分区本质上都是存储在 Apache BookKeeper 中的分布式日志。Topic 可以有多个分区,分区数据持久化时,分区(Partition)是逻辑上的概念,实际存储的单位是分片(Segment)的,例如下图中的一个分区 Topic0-Part1 的数据由多个 Segment 组成, 每个 Segment 作为 Apache BookKeeper 中的一个 Ledger,根据每一个Bookie的负载情况均匀分布并存储在 Apache BookKeeper 群集中的多个 Bookie 节点中, 每个 Segment 具有 3 个副本,当然这是一个可配参数–write quorum。
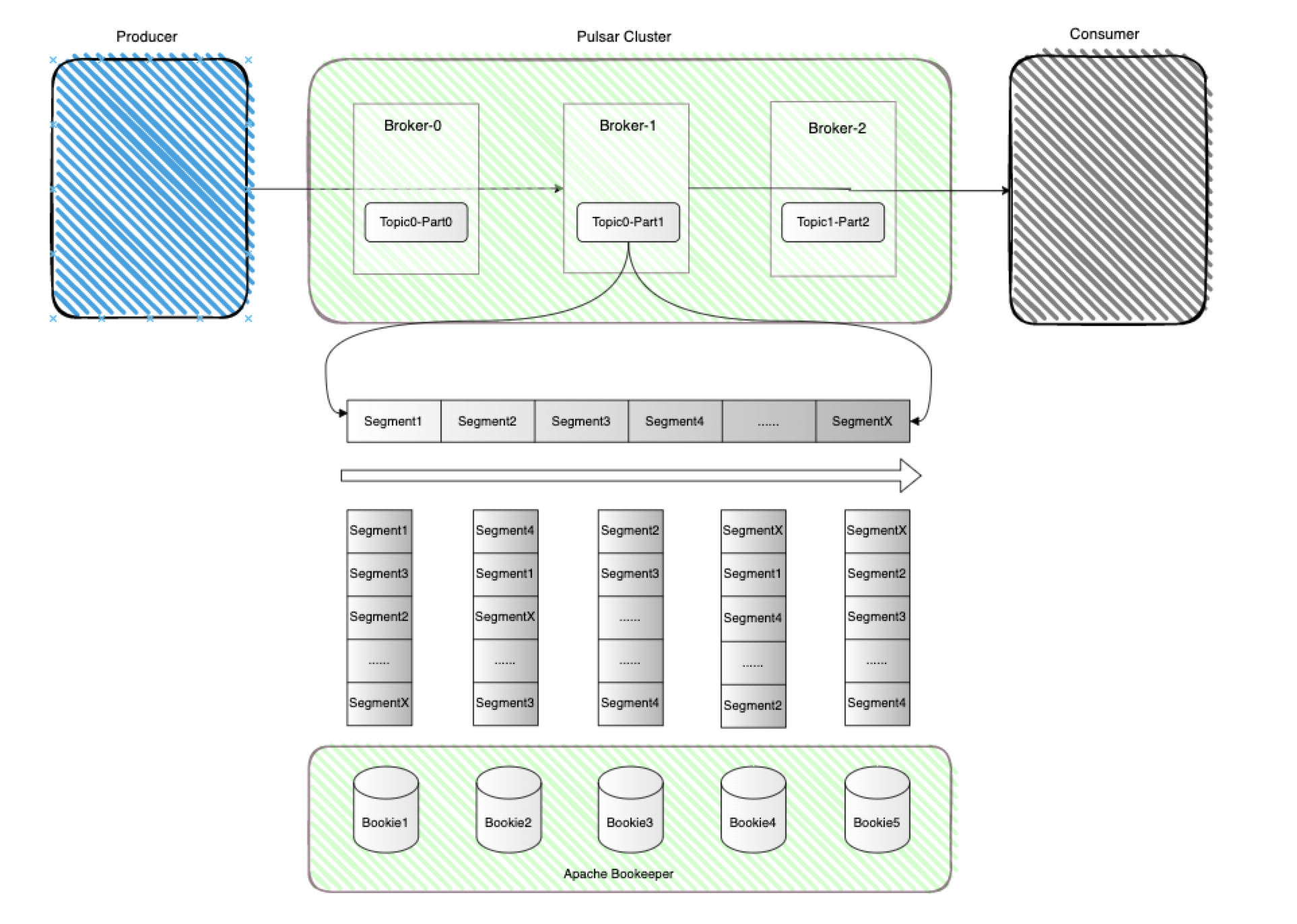
写到这里,让我们先来总结一下:
Kafka采用的是物理分区模型如下图左 :
Pulsar采用的是逻辑分区物理分片的模型如下图右 :
从云原生的角度来讲肯定是右下的分区模型更为合适的,因为这种模型更适合动态上下线以及动态扩容。
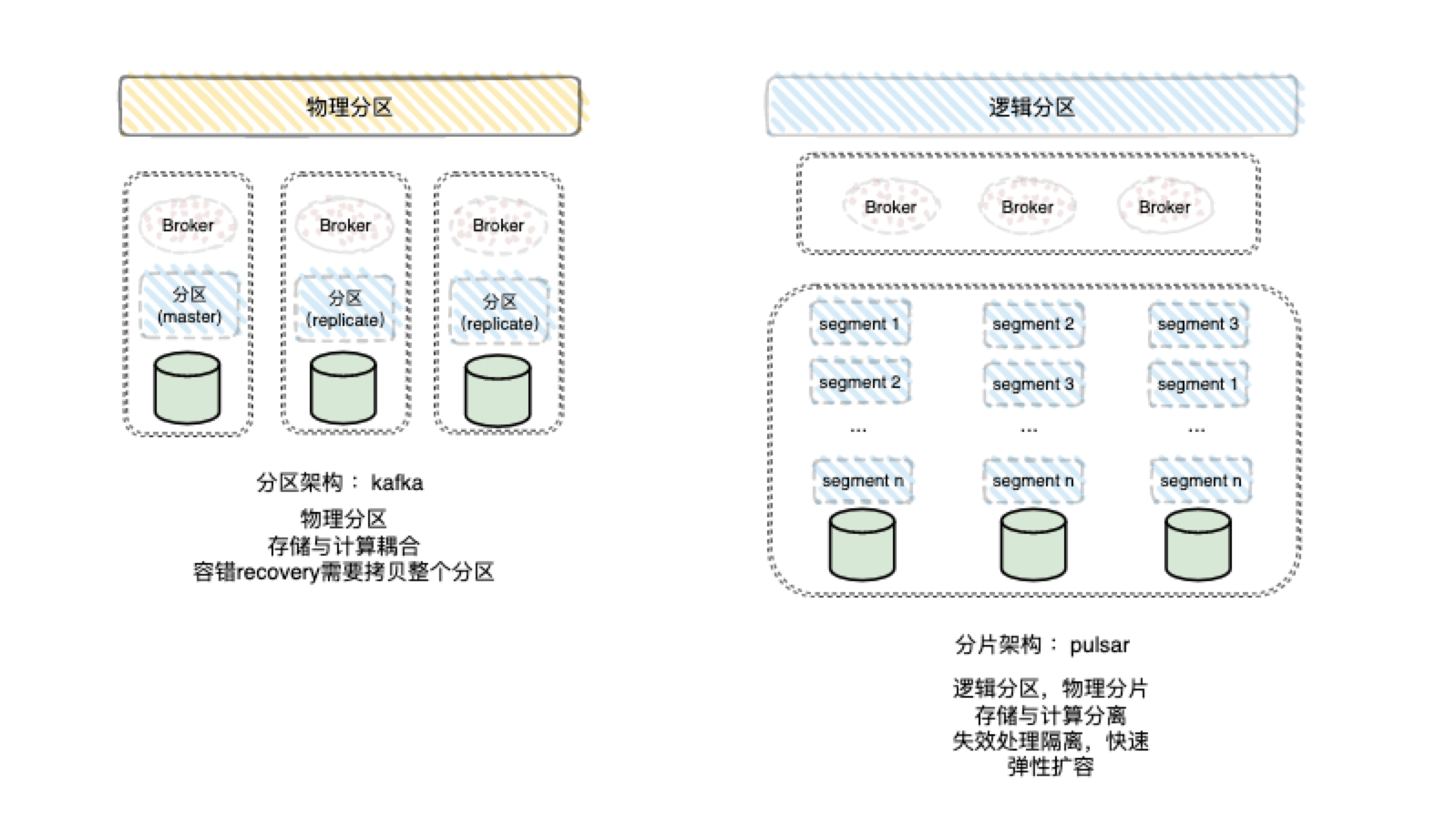
Pulsar架构的优势
Pulsar的这种架构设计优点有如下几点:
- Broker(计算) 和 Bookie(存储) 相互独立,方便实现独立的扩展以及独立的容错;
- Broker 无状态,便于快速上、下线,更加适合于云原生场景;
- 底层采用分区存储不受限于单个节点存储容量;
- 分区数据由于有负载的存在数据分布均匀;
高扩展性
由上面的介绍可知,Pulsar的计算与存储是完全独立的,所以在系统的扩展性上面也是可以分开来看待的.
Broker
Broker是无状态(Stateless)的,可以通过增加节点和删除节点的方式实现快速扩缩容。当流量陡增你需要更多的生产者和消费者来提升系统的吞吐量时,我们可以简单方便地添加 Broker 节点来满足业务需求。Pulsar 支持自动的分区负载均衡,在 Broker 节点的资源使用率达到阈值时,会将负载迁移到负载较低的 Broker 节点,这个过程中分区也将在多个 Broker 节点中做平衡迁移,一些分区的所有权会转移到新的Broker节点。
Bookie
存储层的扩容则由Bookie节点来掌控,通过资源感知和数据存放策略,流量将自动切换到新的 Bookie 节点中,整个过程不会涉及到不必要的数据搬迁,即不需要将旧数据从现有存储节点重新复制到新存储节点, 要知道kafka在这件事情上面是需要复制整个partition数据的。
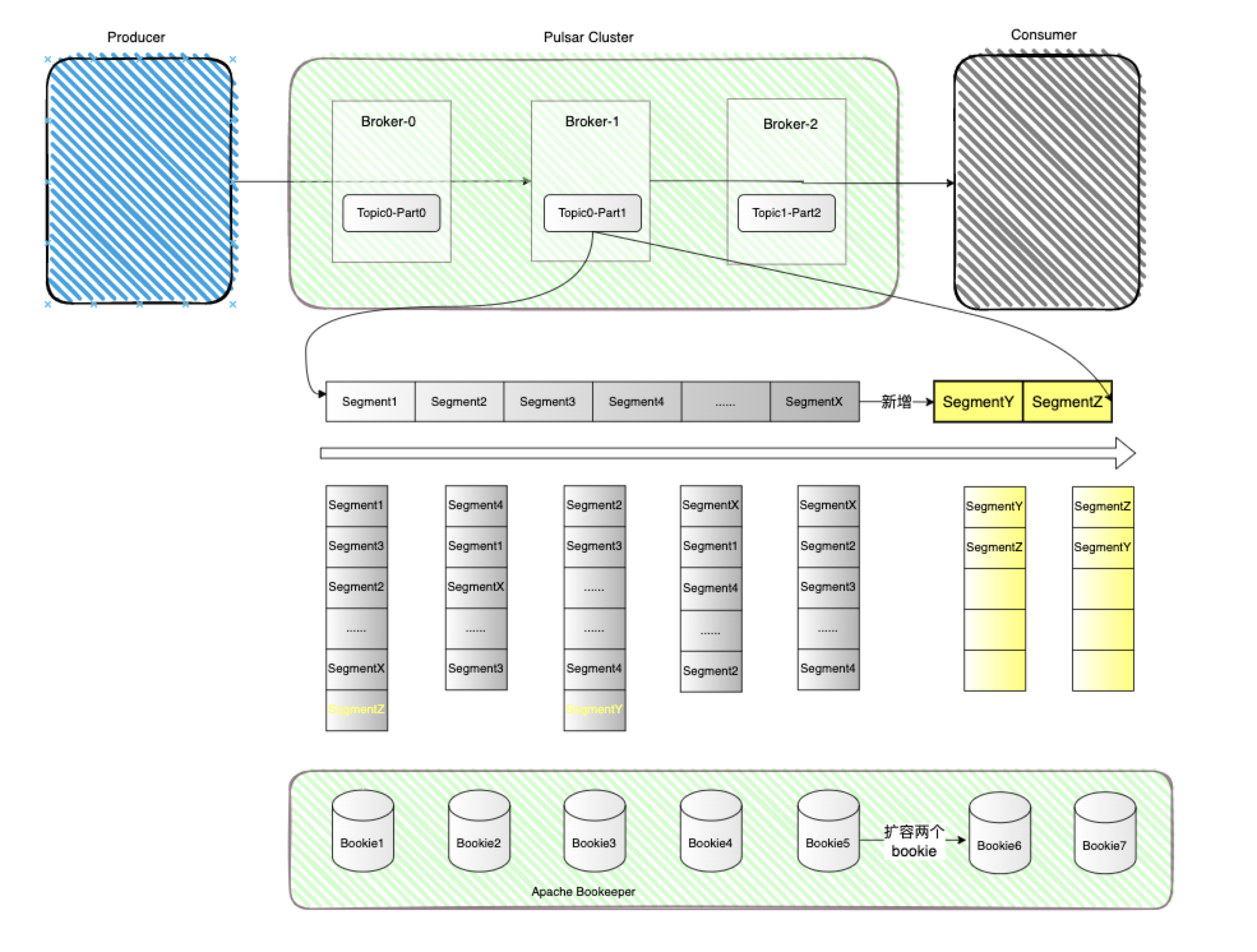
见上图,先大致了解一下存储扩容后数据存放的逻辑,例如起始状态有5个存储节点,Bookie1, Bookie2, Bookie3, Bookie4, Bookie5,以 Topic0-Part1来说,当这个分区的最新的存储分片是 SegmentX 时,此时由于某种原因对存储层bookie进行扩容,添加了两个新的 Bookie 节点,Bookie6和Bookie7,那么在存储分片滚动之后,新生成的存储分片, SegmentY和SegmentZ就会会优先选择新的 Bookie 节点(Bookie6,Bookie7)来保存数据,其实整个过程中每个Segment也是需要有一个副本数保证的,上文提到过的write quorum参数控制,在后续的Bookkeeper介绍中我们会详细介绍这几个参数,这里就暂时先提一下,其实在BK层是有三个核心参数的,含义分别如下:
- ensemble size : 在初始化 Ledger 时, 首先要选取一个 Bookie 集合作为写入节点,ensemble 表示这个集合中的节点数目
- write quorum : 数据备份数目
- ack quorum : 响应节点数目
高容错性
扩展说明的是扩展机器,而容错则是说明当集群中的机器由于人为或者一些不可抗因素导致宕掉之后,服务依然能够像没事一样对外稳定提供服务,由于计算存储分离的原因,所以容错性依旧从以下两个方面来看,各自独立。
Broker
先来看看当Broker集群中的某一台机器突然挂掉了,会发生什么了?如下图 :
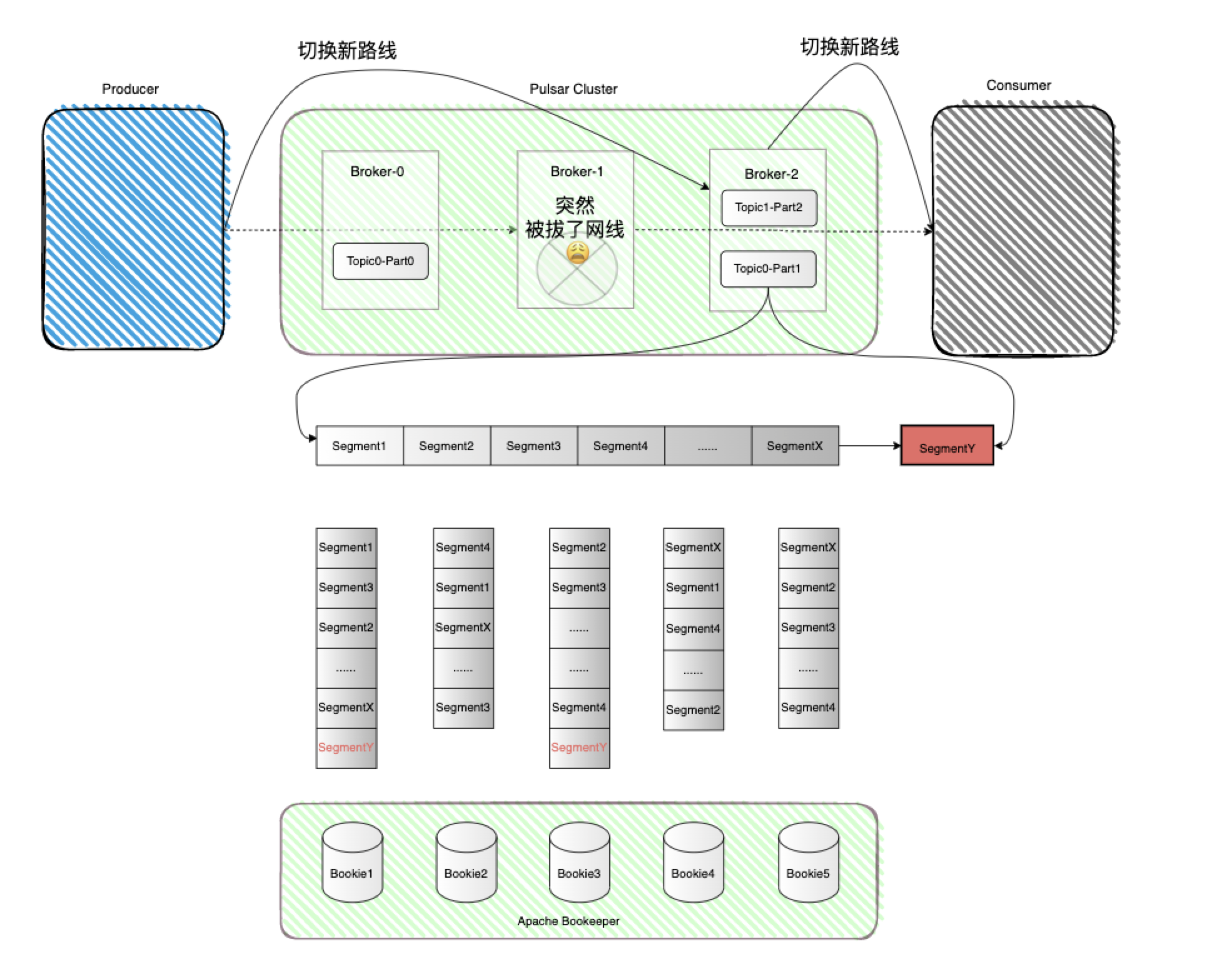
前面我们说了Broker是一个无状态节点,它只负责计算不实际存储数据甚至连元数据信息都没有,所以当Broker-1突然挂掉之后,原本它负责的Topic0-Part1的所有权会根据负载情况自动转移给当前负载较轻的Broker-2节点,整个过程非常的轻便只是发生了一次所有权(ownership)的转移,底层存储并没有任何的影响,也不存在任何的数据拷贝。
Bookie
接下来再看看当某一个存储层的Bookie节点发生无故宕机时会发生什么,如下图所示 :
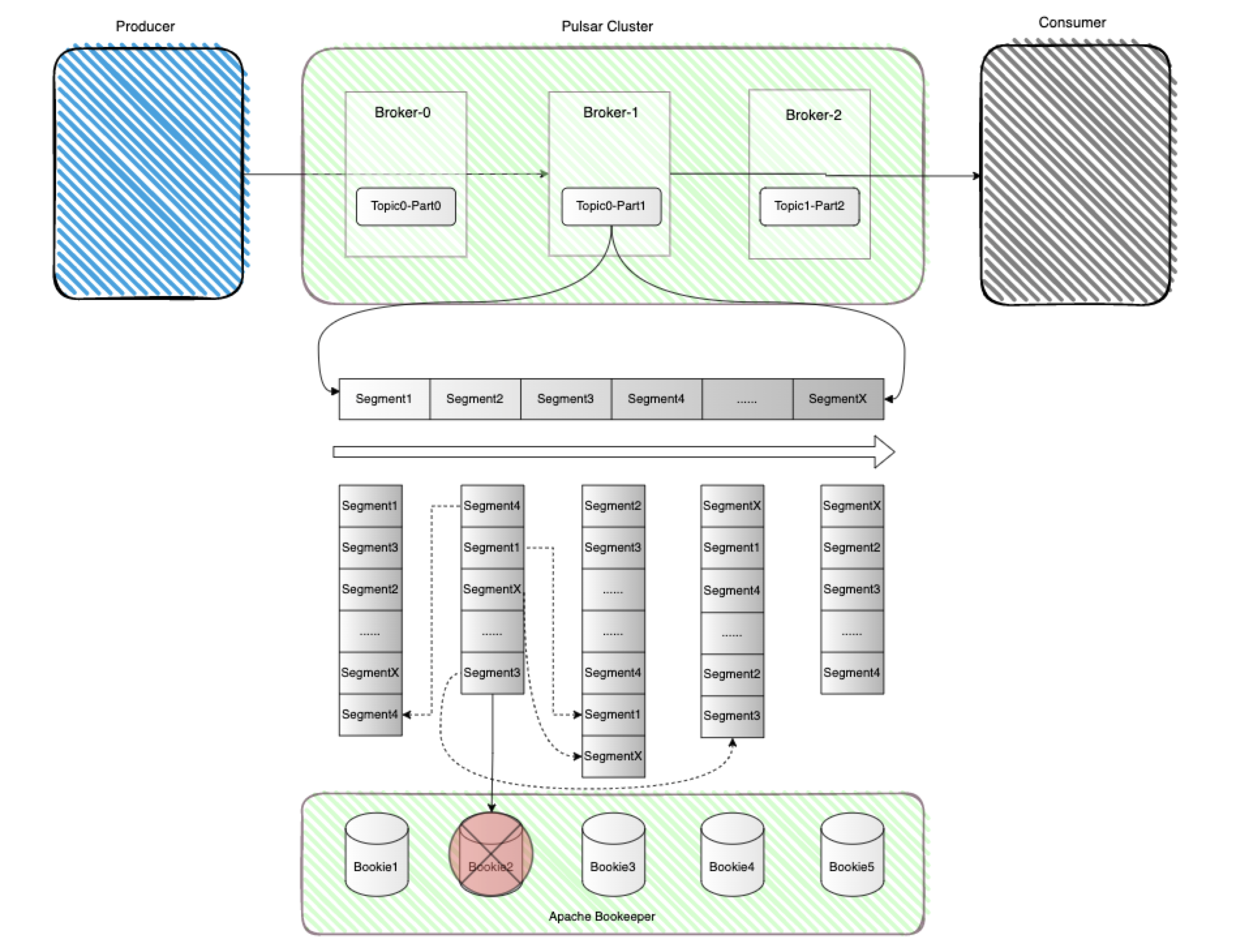
因为Bookie是实际存储数据的地方,所以当Bookie2挂了之后,存储在它上面的数据会根据当前Bookie集群的负载情况对数据按照Segment的级别进行分发,Apache BookKeeper 中的副本修复是 Segment 级别的多对多快速修复,所有的副本修复都在后台进行,对Broker和应用透明,Broker 会产生新的Segment 来处理写入请求,不会影响分区的可用性,至于为什么要按照这样的方式分发,我猜想是为了维持最少副本数的体制内规则。
分区存储的优势在哪
总结一下,其实上从面的分析来看结论其实已经很明显了,分片存储在很大程度上解决了分区容量受单节点存储空间限制的问题,当容量不够时,可以通过快速扩容 Bookie 节点的方式支撑更多的分区数据, 因为新数据的写入会优先考虑新增的Bookie节点并且数据会均匀的分配在 Bookie 节点上,不会造成单点压力过大。 另外Broker 和 Bookie 高容错架构以及无缝的扩容能力让 Apache Pulsar 具备非常高的可用性。
Pulsar特性
读写模型
之前讲Kafka的时候也说过了,一个MQ的核心无非就是读写存,那接下来就来看看Pulsar的读写模型,Pulsar在其实现上最大的优势就是读写分离,那具体是怎么带来好处的,还是先来看张图 :
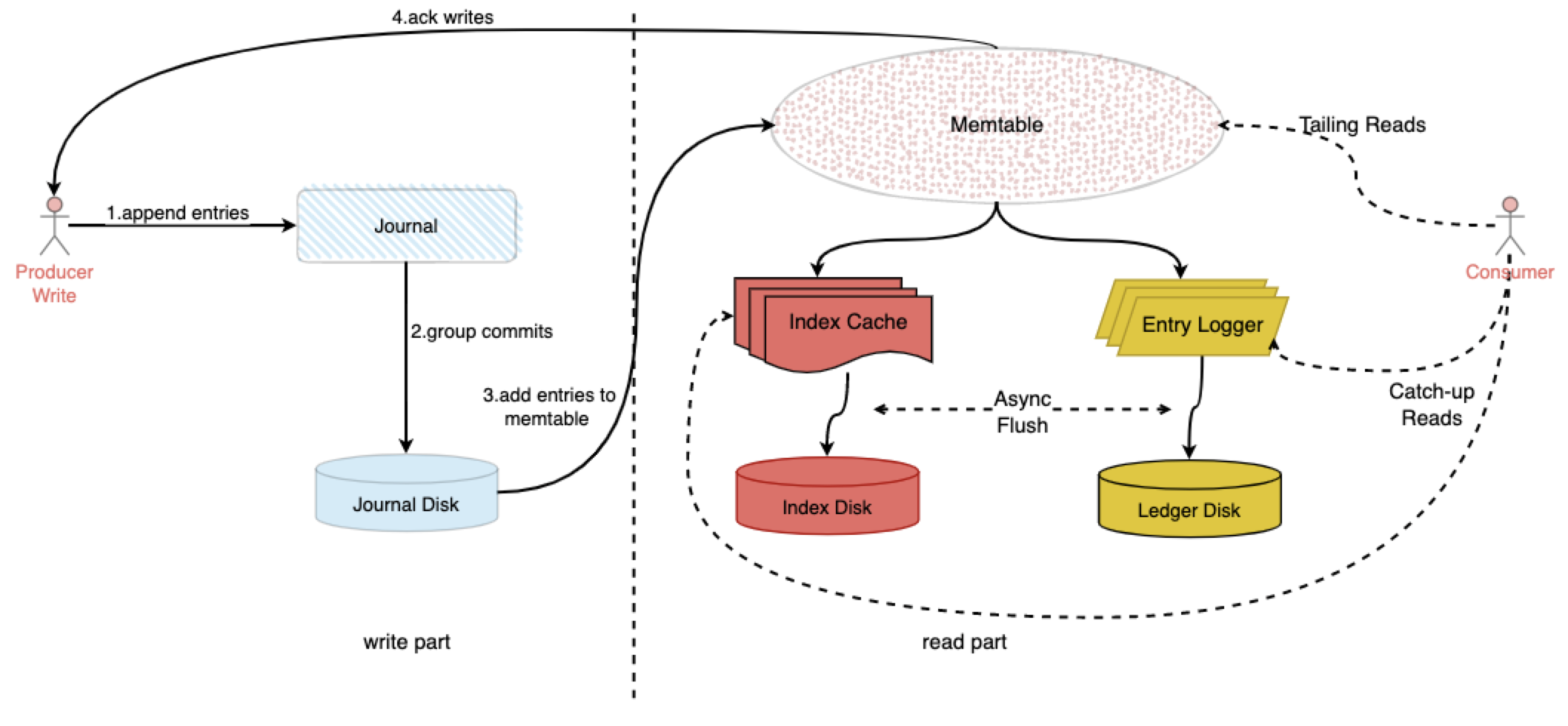
不要慌,初次看到这个图我也是懵逼的但其实本图表达的内容非常简单,容我向诸位一一解释,这张图就是很统筹的介绍了Pulsar的整个读写过程,对图中的名词来进行一下解释:
- Journals:中文可以叫它期刊,Journal 文件包含了 BookKeeper事务日志,在 Ledger 更新之前,Journal 保证描述更新的事务写入到 Non-volatile 的存储介质上
- Entry logs:Entry Logger管理写入的 Entry,来自不同 Ledger 的 Entry 会被聚合然后顺序写入
- Index files:每个 Ledger(账本)都有一个对应的索引文件,记录数据在 Entry 日志文件中的 Offset 信息,这种方式在介绍kafka的时候讲过了
写过程解释 :
- 数据首先会写入 Journal,写入 Journal 的数据会实时落到磁盘,如果你了解Mysql,那应该会想起RedoLog的作用。
- 数据落Journal Disk成功后会写入到 Memtable ,Memtable 就是一个是读写缓存。
- 在写入 Memtable 成功之后,就会对写入者进行Ack响应。
- 最后在 Memtable 写满或者是达到某一个阈值之后,就会 Flush 到 Entry Logger 和 Index cache中,Entry Logger 中保存了实际的消息数据,Index cache 保存了数据的索引信息,最后由后台线程将 Entry Logger 和 Index cache 数据异步落到磁盘。
读过程解释 :
Tailing read (跟踪读),会直接从 Memtable 缓存中读取 Entry , 速度非常快。
Catch-up read(滞后读),会先读取 Index信息,然后根据index信息再从 Entry Logger 文件读取 Entry,会有磁盘io的发生,速度较慢。
这里提出一个问题,那是什么样的场景下会分别用到上面两种读方式了?
Ok,现在回头再来看看我的中文翻译版,相信这张图此时对你就没什么难度了 :
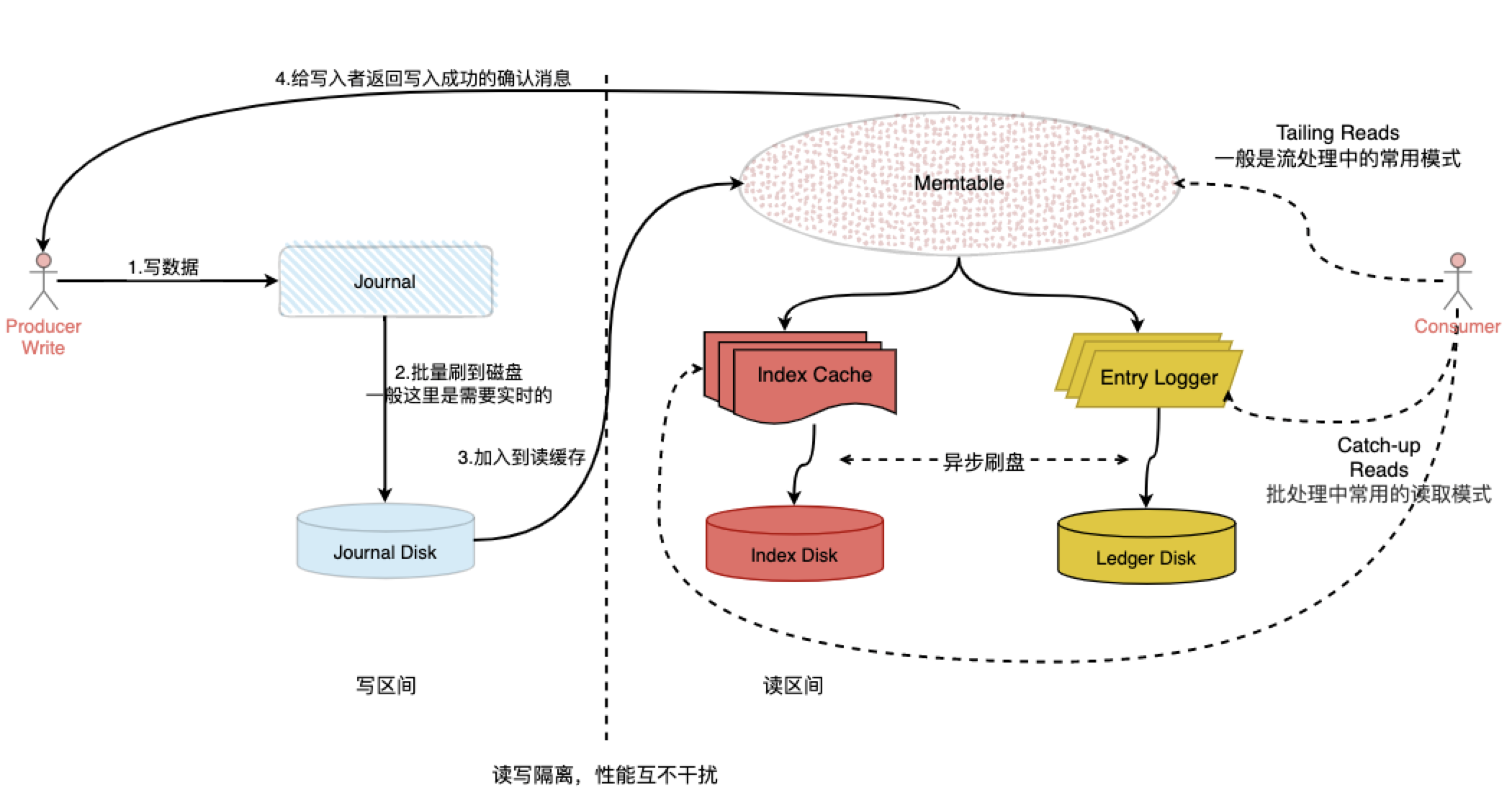
很明显在上述的读写分离的模型中,能看出只有Journal的写入是需要同步的将每一条日志进行落盘处理的,这一点决定的pursal是否会在写入时丢消息,所以一般情况下推荐Journal要使用性能较高的SSD磁盘,至于读区间的磁盘也是需要与其隔离开来的避免相互的性能影响的。所以,数据写入主要是受 Journal 磁盘的负载影响,不会受Ledger 磁盘的影响。当然这并不是说Ledger 磁盘也不需要性能考虑,只是说 Journal 磁盘的性能更为重要~
消息的消费模型
其实之前的一篇简文中也介绍过了,这里就再总结介绍一下: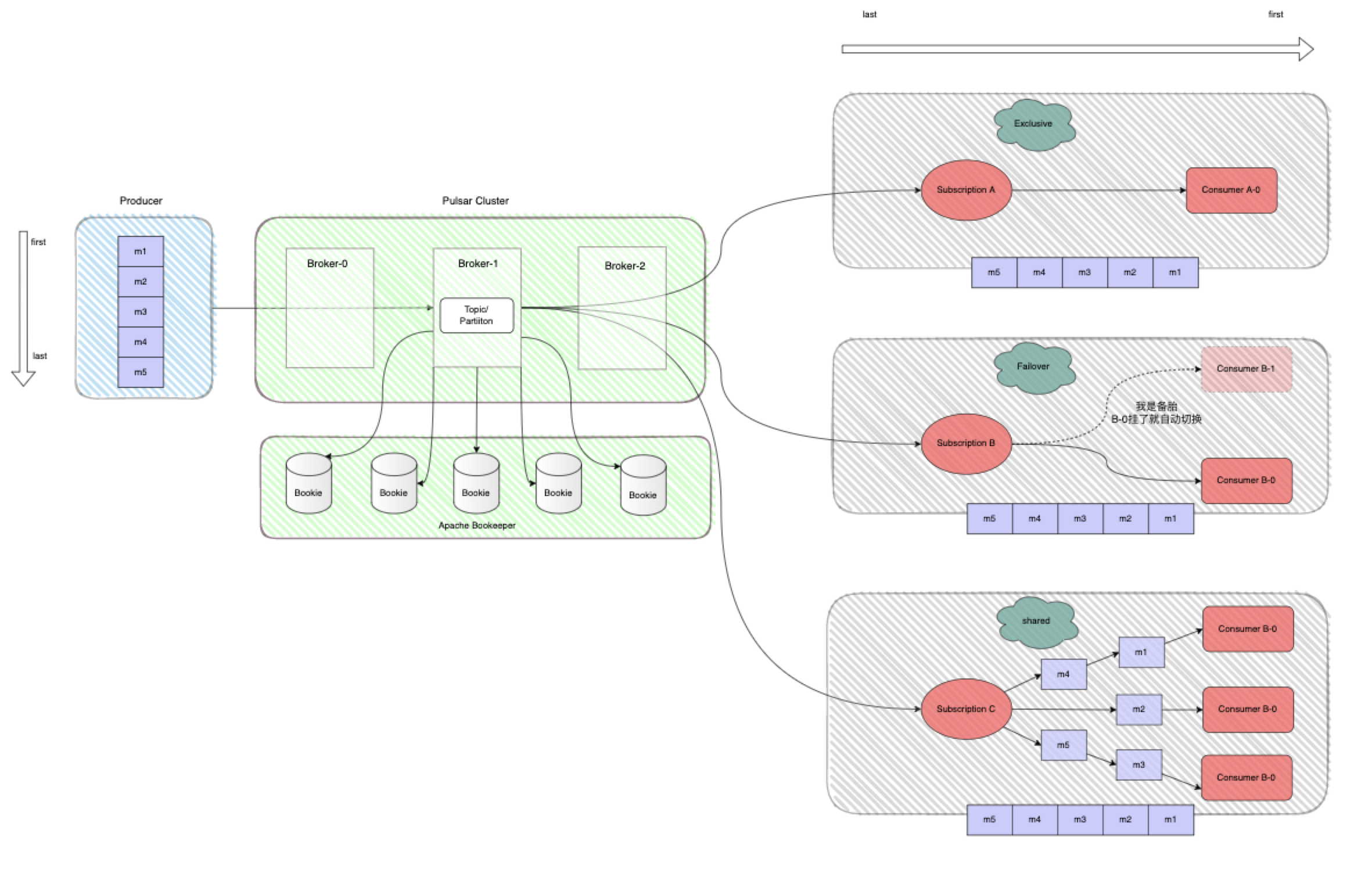
不同的消费模型决定了每一条消息的处理方式,Pulsar提供了四种消费模型 分别是独占(Exclusive),故障切换(Failover),共享(Share)以及 key共享(key-Share),上图给出了前三种的处理方式,至于第四种其实与第三种是一样的,只是多了一项可以根据key分发到指定的消费者。解释一下 :
Exclusive :永远都有且只能有一个消费者组(订阅)中有且只有一个消费者来消费 Topic 中的消息。
Failover :多个消费者(Consumer)可以同时订阅同一个Topic。 但是,一个订阅中的所有Consumer,有且只有一个Consumer被选为该订阅的主Consumer。 其他Consumer将被指定为故障转移Consumer也就是备胎。 当主Consumer断开连接或者发生故障时,分区将被重新分配给其中一个备胎,而新分配的Consumer将成为新的主消费者获得转正。 如果此时故障Consumer中存在没有ack的消息,那这些消息将会被重传至最新的主Consumer。
Share :又叫共享订阅,是实际工作中使用最多的一种模式,同一个订阅用户按照应用的需求挂载任意多的消费者。 订阅中的所有消息以循环分发形式发送给订阅背后的多个消费者,并且一个消息仅传递给一个消费者。当消费者断开连接时,所有传递给它但是未被确认(ack)的消息将被重新分配和组织,以便发送给该订阅上剩余的剩余消费者。
补充一点,在kafka中是用Consumer Group为单位来进行消息消费的,而在Pulsar中则是用Subscription为单位。现在来回答上面提出的一个问题 :那是什么样的场景下会分别用到上面两种读方式了?Exclusive和Failover这种stream处理模式会大量用到Tailing read (跟踪读),而Share这种Queun模式则会大量的使用Catch-up read(滞后读)。
消息的确认机制
确认机制是所有消息队列中非常核心的一步,它可以避免消息的重复投递以及消息是否投递成功,Pulsar的消息确认总体分为Client确认和Broker确认,下面来一一详细介绍一下!
客户端确认
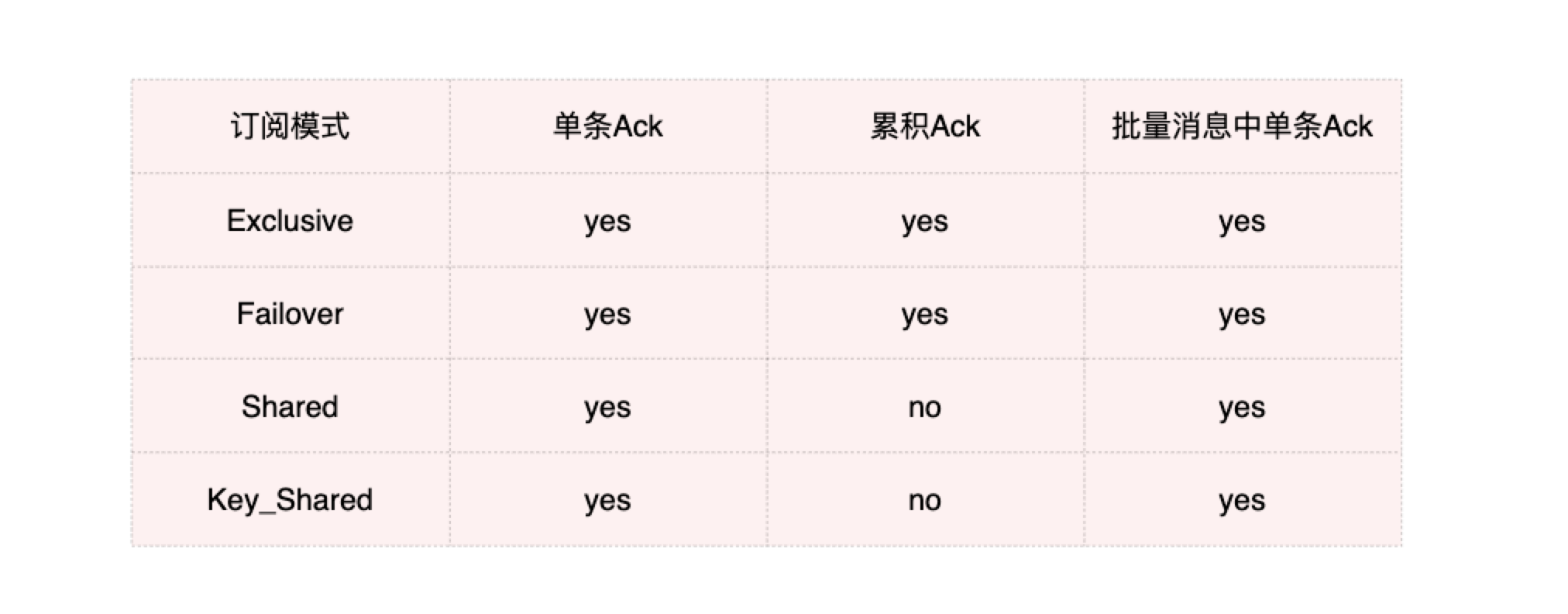
通过上面所述我们知道在Pulsar中有多种消费模式,如:Share、Key_share、Failover和Exclusice,但无论使用哪种消费模式其实都会创建一个Subscription(订阅)。Subscription分为持久化订阅(Persistent-subscription)和非持久化订阅(Nonpersistent-Subscription),对Persistent-Subscription而言,Broker上会有一个对应持久化的游标(Cursor),记住这个名词,它是Pulsar中非常重要的一个对象,上文提到过元数据被记录在ZooKeeper,因此Cursor也不例外。Cursor以Subscription为单位,保存了当前Subscription已经消费到哪个位置了。因为不同Consumer使用的Subscription模式不同,可以进行的Ack行为也不一样。总体来说可以分为以下几种Ack场景:
- 单条确认(Individual Ack),单独确认一条消息。 被确认后的消息将不会被重新传递。和kafka不同,Pulsar的一个Partition是允许被多个消费者消费的。这里假定消息1、2发送给了Consumer-A,消息3、4发送给了Consumer-B,消息5、6发送给了Consumer-C,其中Consumer-C消费的比较快,先Ack了消息5,此时Cursor中会单独记录消息5为已Ack状态。如果其他消息都被消费,但没有被Ack,并且三个消费者都下线或Ack超时,则Broker会只推送消息1、2、3、5、6,已经被Ack的消息4不会被再次推送。
- 累积确认(Cumulative Ack),通过累积确认,消费者只需要确认它收到的最后一条消息。与上面的单条确认有差异,假设Consumer-A接受到了消息1、2、3、4、5、6,为了提升Ack的性能,Consumer 并不需要去对这每一条消息都进行ack,而是只需要调用一次AcknowledgeCumulative,然后把位置最后的消息6传入,那Broker会把消息6以及之前的消息全部标记为已Ack,只需要一次Ack即可。
- 累积确认(Cumulative Ack)中的单条确认。这种消息确认模式,调用的接口和单条消息的确认一样。与上面的累积确认一致,只是它可以指定确认某一批消息中的某几条,例如Consumer-A拿到了一个批消息,里面有消息1、2、3、4、5、6,如果不开启Broker中的AcknowledgmentAtBatchIndexLevelEnabled,那就只能消费整个Batch后再统一Ack,否则Broker会以批为单位重新全部投递一次。前面介绍的选项开启之后,我们可以通过Acknowledge方法来确认批消息中的单条消息。
- 否定确认(NegativeAcknowledge)客户端发送一个RedeliverUnacknowledgedMessages命令给Broker,明确告知Broker这条消息我这个客户端暂时处理不了等会再来试试,那么消息将会被重新投递,讲到这里其实又延伸出了另外一个MQ中的核心话题—消息重试,下一张实践篇会详细解析Pulsar中的消息重试方案实现。
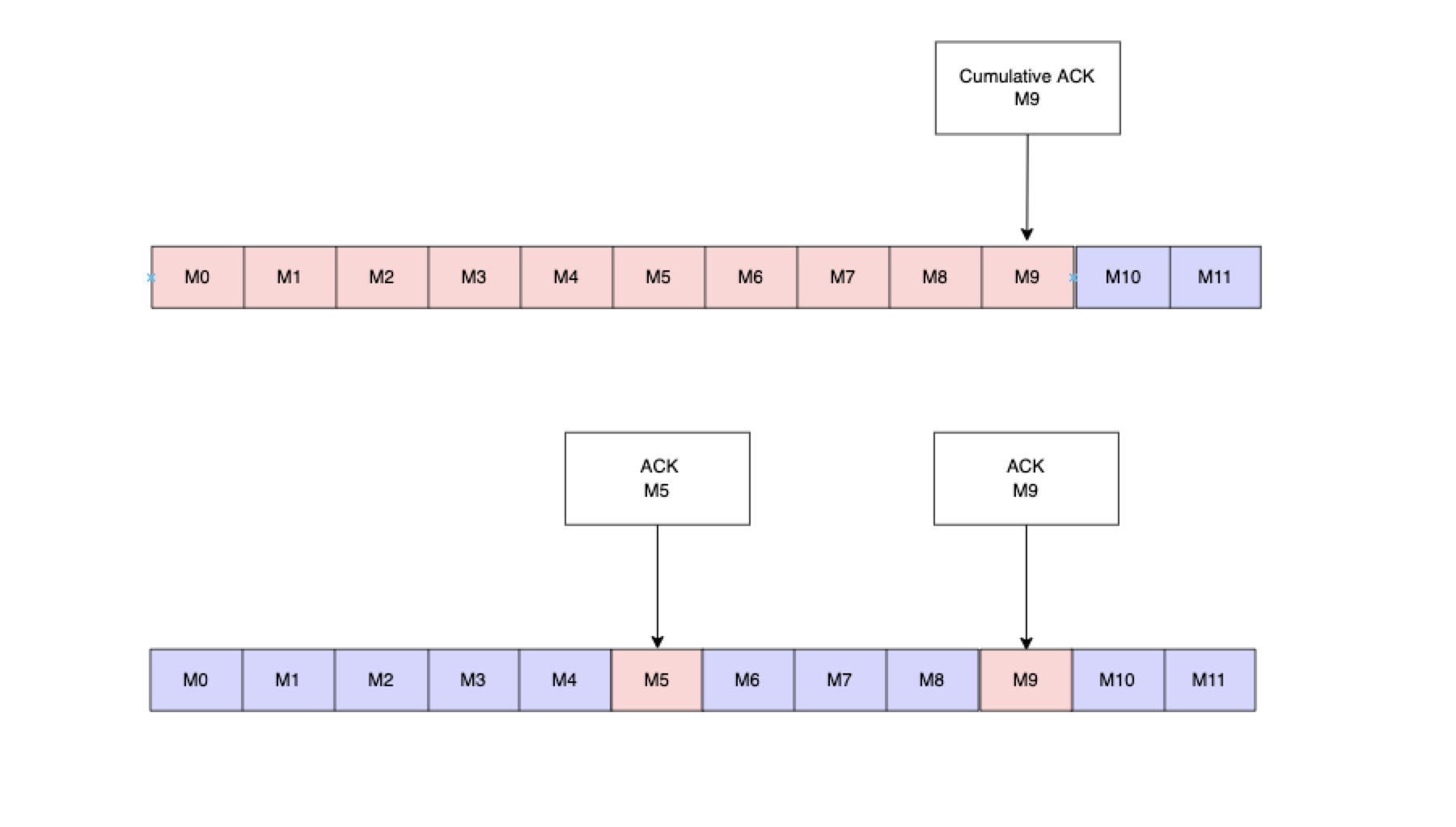
看下图中上下分别代表累计确认和单条确认(浅灰色框中的消息代表被ACK)。在累计确认中,M10 之前的消息被标记为 Acked。在单条确认中,仅仅只是确认消息 M5 和 M9, 当消费者失败或者重启等情况下,除了 M5 和 M9 之外,其他所有消息将被重新传送至消费端。
提出一个问题~之前不是说过Pulsar中的一个Partition中的数据是可以被多个Consumer消费的吗,假定这样的场景消息1、2发送给了Consumer-A,消息3、4发送给了Consumer-B,消息5、6发送给了Consumer-C,此时还能用批量确认吗?答案显示是不能的,如果Consumer-C处理速度较快而A和B对应的消息是会处理失败的,这时C处理完了发了一个6的Ack,那不是把A和B的消息也给Ack了吗?这显然是不对的,所以在Pulsar中订阅模式与消息确认之间的关系有如下所示关系:
Acknowledge和AcknowledgeCumulative实现原理
从性能的角度出发,Pulsar在做任何Ack操作时都不会一条条给Broler发送Ack信号,而是把请求转交给AcknowledgmentsGroupingTracker处理。记住它,这是本文介绍的第一个Tracker,它只是一个接口,接口下有两个实现,一个是持久化订阅的实现,另一个是非持久化订阅的实现。由于非持久化订阅的Tracker是空实现,就没有介绍的必要了,本文只对persistent-Subsription的实现——PersistentAcknowledgmentsGroupingTracker来做介绍。
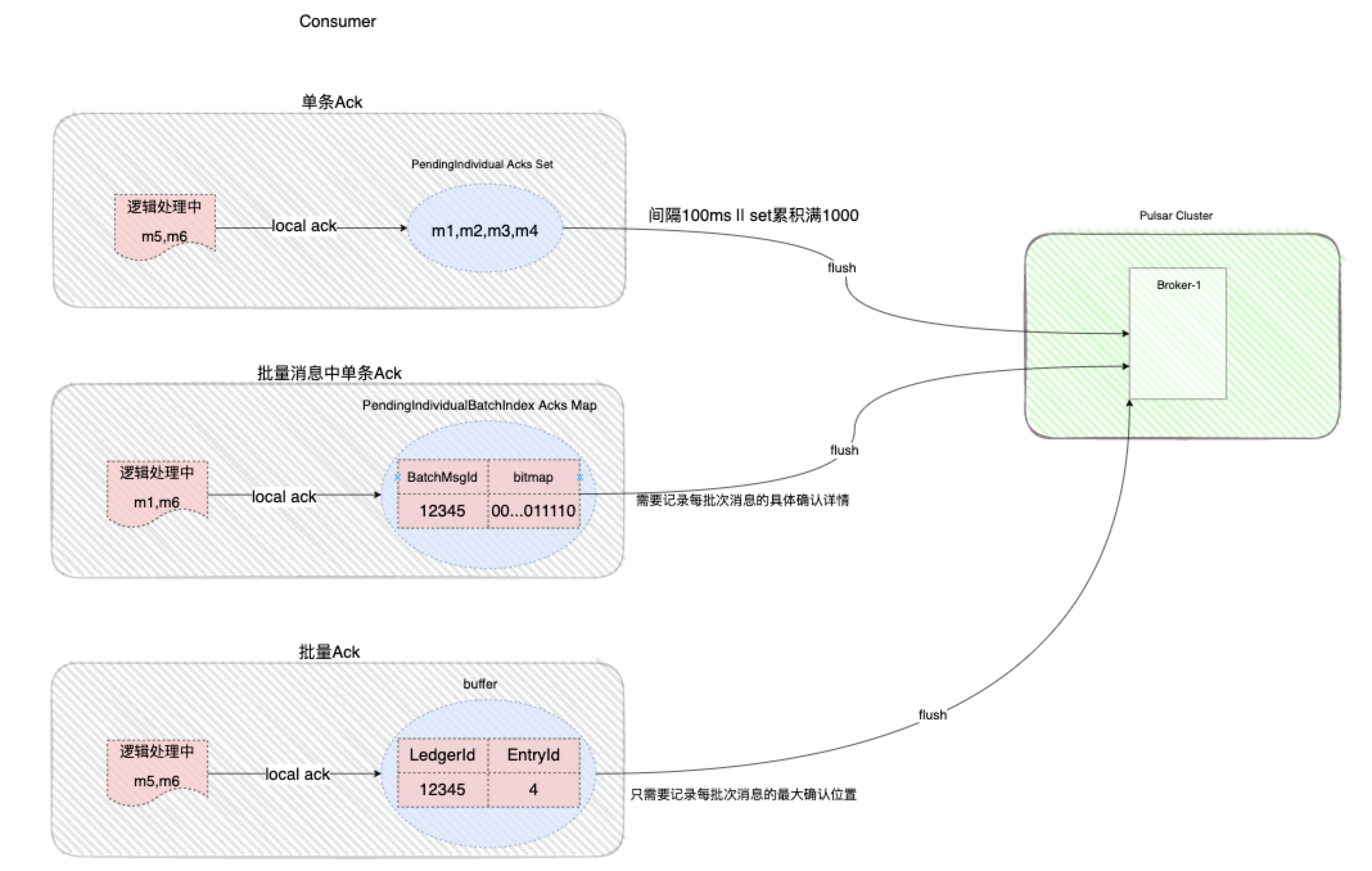
上面提到了从性能的角度考虑,Tracker是默认批量确认的,即使是单条消息的确认,也会先进入Consumer本地缓冲队列,然后再一批次的发往Broker。在创建Consumer时可以设置参数AcknowledgementGroupTimeMicros,如果设置为0,则Consumer每次都会立即发送确认请求。所有的单条确认(IndividualAck)请求会先放入一个名为PendingIndividual Acks的Set,默认是每100ms或者堆积的确认请求超过1000,则发送一批确认请求
对于Batch消息中的单条确认(IndividualBatchAck),则用一个名为PendingIndividualBatchIndexAcks的Map进行保存,而不是普通单条消息的Set。这个Map的Key是Batch消息的MessageId,Value是一个BitMap,记录这批消息里哪些需要Ack。使用BitSet能大幅降低保存消息Id的能存占用,1KB==1024*8bit 就能记录8192个消息是否被确认。由于BitMap保存的内容都是非0即1,因此可以很方便地保存在堆外,BitMap对象也做了池化,可以循环使用,不需要每次都创建新的,对内存非常友好,顺带提一句BloomFilter也是用BitMap来实现的。
对于累计确认(CumulativeAck)实现方式就相对比较简单了,Tracker中只保存最新的确认位置点即可。
最后就是Tracker的Flush,所有的确认最终都需要通过触发Flush方法发送到Broker,但无论是哪种确认,Flush时创建的都是同一个命令并发送给Broker,不过是传参中带的AckType会不一样。来看一张总结图加强一下认识:
NegativeAcknowledge的实现
NegativeAcknowledge一般又叫NAck,同上面一样,NAck和其他消息确认方式是一样的,并不会单条立即请求Broker,而是把请求转交给NegativeAcksTracker进行处理。记住它,这是本文介绍的第二个Tracker,该Tracker中记录着每条消息以及需要延迟的时间。Tracker复用了PulsarClient的时间轮,默认是33ms左右一个时间刻度进行检查,默认延迟时间是1分钟,抽取出已经到期的消息并触发重新投递。Tracker主要存在的意义是为了合并请求。另外如果延迟时间还没到,消息会暂存在内存,如果业务侧有大量的消息需要延迟消费,还是建议使用ReconsumeLater接口。NegativeAck唯一的好处是,不需要每条消息都指定时间,可以全局设置延迟时间。
未确认消息的处理
在讨论以下问题之前,需要先来了解一下一个新的概念叫预拉取,其实Consumer从Broker拿消息时并不是一条一条拿的,而是Broker出于性能考虑一次性推送一批数据至Consumer然后放在一个本地预拉取队列(ReceiveQueue)里面,该队列的大小由参数ReceiveQueueSize控制,由这里的逻辑我们要知道在创建消费者设置ReceiveQueueSize参数时需要十分慎重,避免大量的消息堆积在某一个Consumer的本地预拉取队列,而其他Consumer又没有消息可消费,造成其他Consumer饥饿。见下图 :
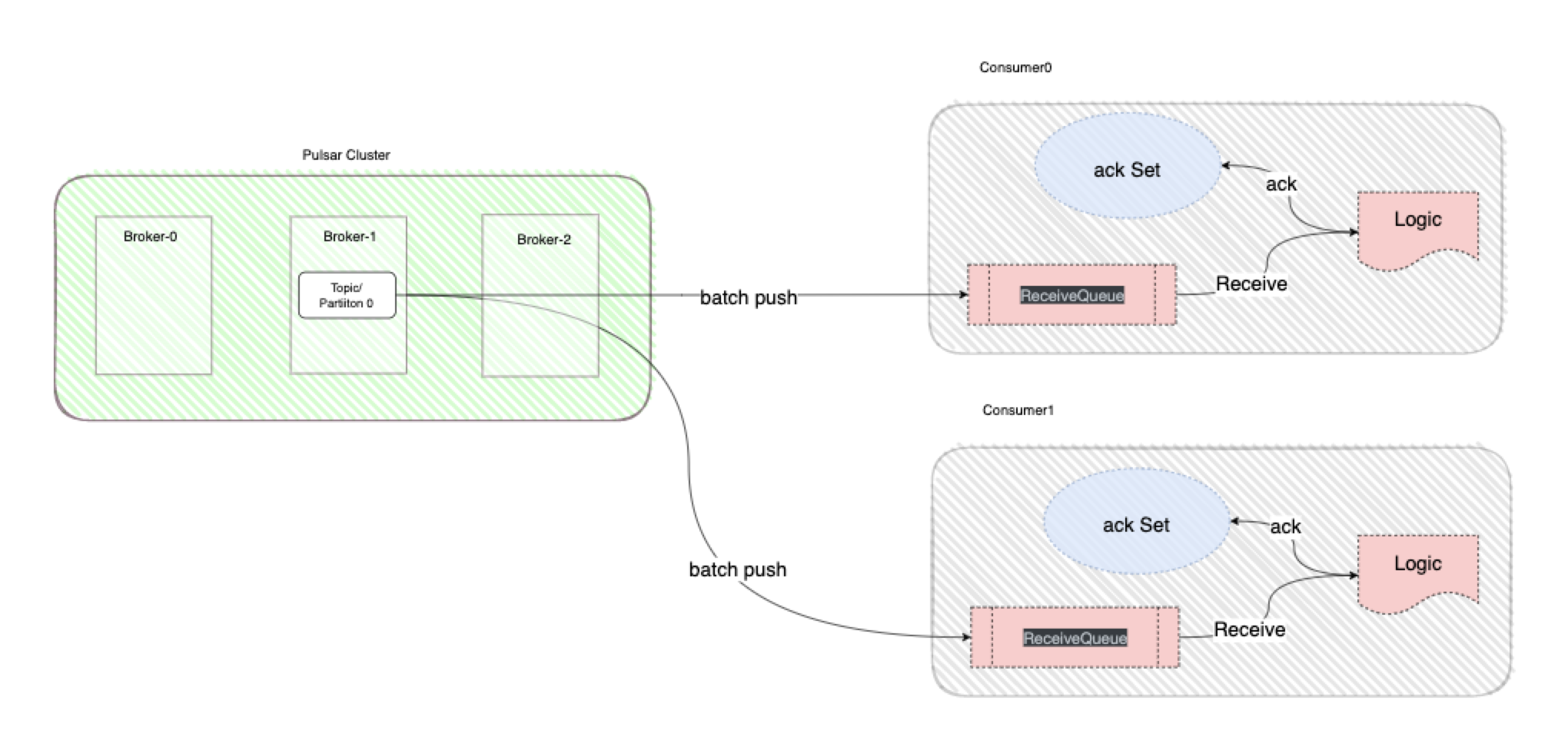
了解了预拉取之后现在我们就可以来探讨下面的问题了,如果消费者获取到消息后一直不Ack也不NAck会怎么样?这个问题需要分为以下两种情况来讨论 :
消息已存ReceiveQueue并且Logic已经调用了Receive方法,或者已经回调了正在异步等待的消费者
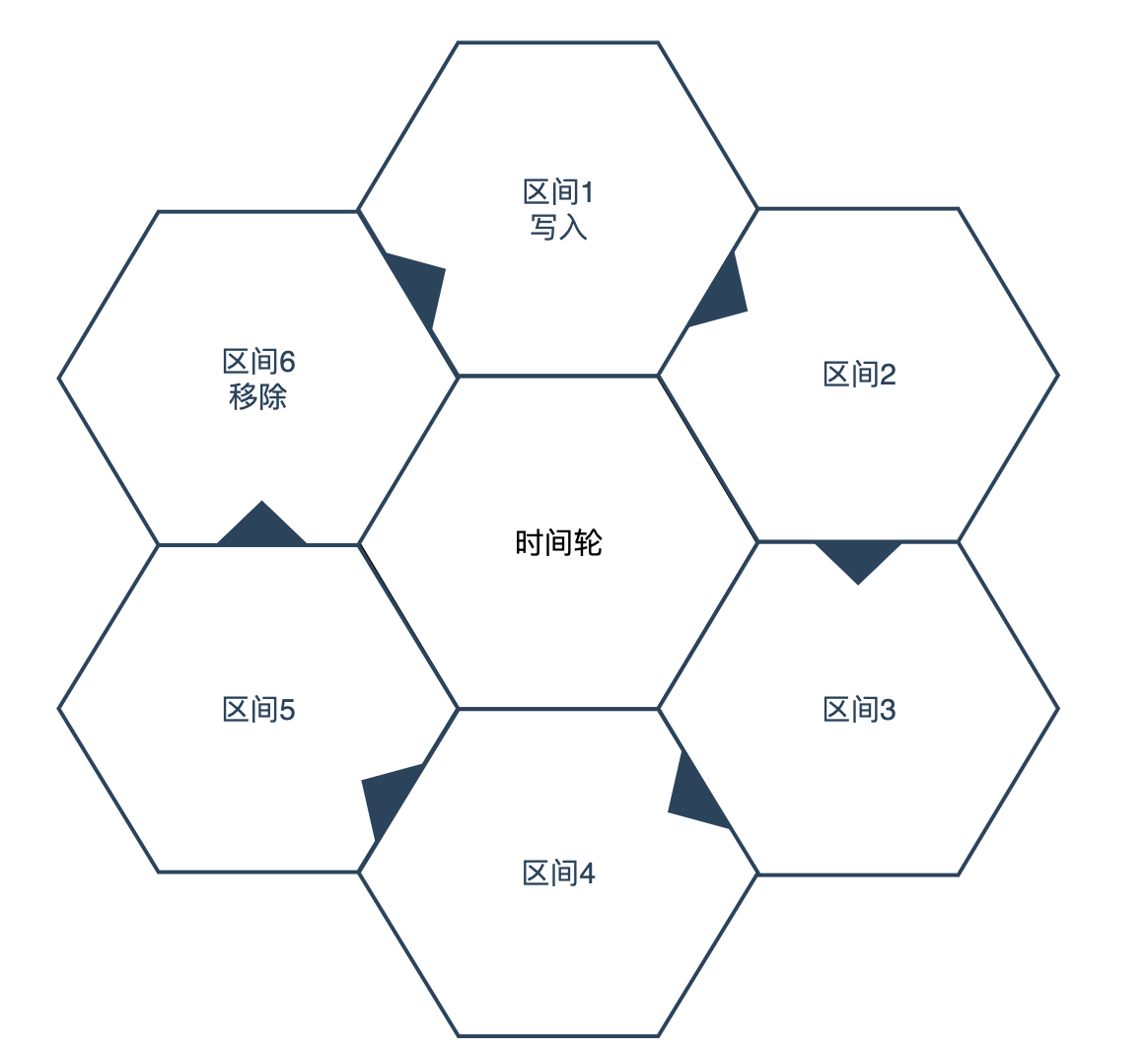
此时消息的引用会被保存进UnAckedMessageTracker,记住它这是本文介绍Consumer里的第三个Tracker。UnAckedMessageTracker中维护了一个时间轮,时间轮的刻度根据AckTimeout、TickDurationInMs这两个参数生成,每个刻度时间=AckTimeout / TickDurationInMs。新追踪的消息会放入最后一个刻度,每次调度都会移除队列头第一个刻度,并新增一个刻度放入队列尾,保证刻度总数不变。每次调度,队列头刻度里的消息将会被清理,UnAckedMessageTracker会自动把这些消息做重投递。重投递就是客户端发送一个RedeliverUnacknowledgedMessages命令给Broker。每一条推送给消费者但是未Ack的消息,在Broker侧都会有一个集合来记录(PengdingAck),这是用来避免重复投递的。触发重投递后,Broker会把对应的消息从这个集合里移除,然后这些消息就可以再次被消费了。注意,当重投递时,如果消费者不是Share模式是无法重投递单条消息的,只能把这个消费者所有已经接收但是未ack的消息全部重新投递。下图是一个时间轮的简单展示,简单了解一下就行:
消息已存ReceiveQueue但是Logic还未调用Receive方法
此时消息会一直堆积在本地队列ReceiveQueue中。预拉取队列可以在创建消费者时通过ReceiveQueueSize参数来控制预拉取消息的数量。Broker侧会把这些已经推送到Consumer本地的消息记录到PendingAck中,并且这些消息也不会再投递给别的消费者,且不会Ack超时,除非当前Consumer宕机或被关闭,消息才会被重新投递。Broker侧有一个Redelivery Tracker接口,暂时的实现是内存追踪(InMemoryRedeliveryTracker)。这个Tracker会记录消息到底被重新投递了多少次,每条消息推送给消费者时,会先从Tracker的哈希表中查询一下重投递的次数,和消息一并推送给消费者。
最后提一点,PulsarClient上可以设置启用ConsumerStatsRecorder,启用后,消费者会在固定间隔会打印出当前消费者的metrics信息,例如:本地消息堆积量、接受的消息数等,方便业务排查性能问题。
Broker确认
客户端Ack或者NAck的消息最终都会发回确认信息到Broker,那Broker侧是如何进行处理的了?这里就是上文提到的游标(Cursor)的舞台了,其实客户端通过消息确认机制通知Broker哪一些消息已经被消费,告知后面就不要再重复发送这些消息了。Broker侧就是使用Cursor游标来存储当前订阅的消费位置信息,包含了消费位置中的所有元数据,避免Broker重启后,消费者要从头消费的问题。上文其实也说了Pulsar中的订阅分为持久订阅(Persistent-subscription)和非持久订阅(Nonpersistent-subscription),区别就是:持久订阅的游标(Cursor)是持久化的,元数据会保存在ZooKeeper,而非持久化游标只保存在Broker的内存中在broker重启后就有可能会重复发数据。
什么是游标(Cursor)
之前说过在Pulsar中任何统计都是以Subscription(订阅)为单位的,所以Cursor(游标)也不例外,比如多个消费者持有同一个订阅名(在kafka中叫ConsumerGroup(消费组)),那这些消费者们就会共享一个游标。游标的共享又和消费者的消费模式有关,如果是Exclusive或者FailOver模式的订阅,那同一时间只有一个消费者可以使用这个游标。如果是Shared或者Key_Shared模式的订阅,那多个消费者会同时共享这个游标。
接下来就来介绍一下当消费者Ack一条消息时Broker中的游标会有一些什么样的变化~每当消费者Ack一条消息,游标中指针的位置有可能会变化也有可能不会发生变化!!!这并不是废话文学,要理解这句话就需要先来回顾一下上一个章节介绍的客户端确认方式,在客户端确认中我们介绍了Ack的几种方式,分别是单条消息确认(Acknowledge)、批消息中的单个消息确认(Acknowledge)、累积消息确认(AcknowledgeCumulative)和否定应答(NAck),但是因为Nack不会涉及游标的变化,所以这里就不做讨论了。
我们先看单条消息的确认,如果是独占式的消费,每确认一条消息,游标位置都会往后移动一个Entry(这里假设客户端Ack一条消息就会发回到Broker,实际上并不是)如下图所示:
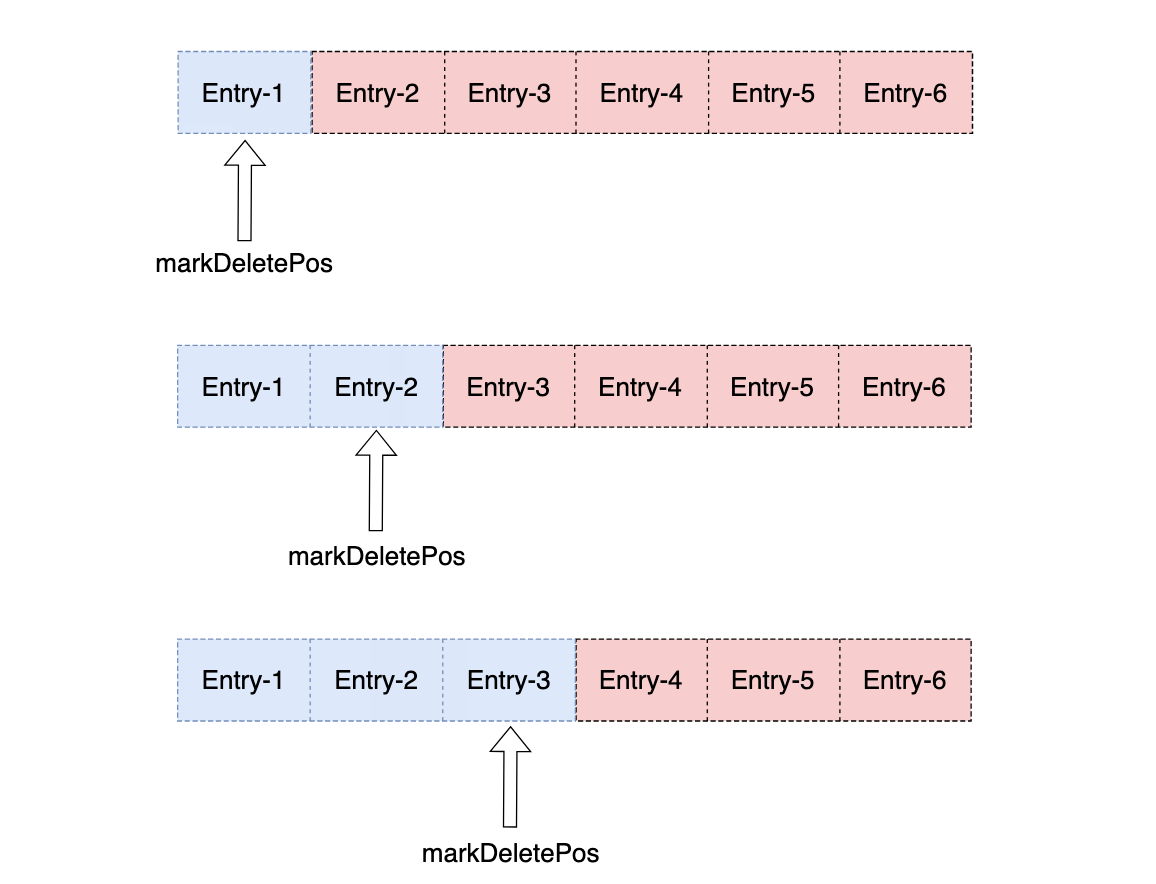
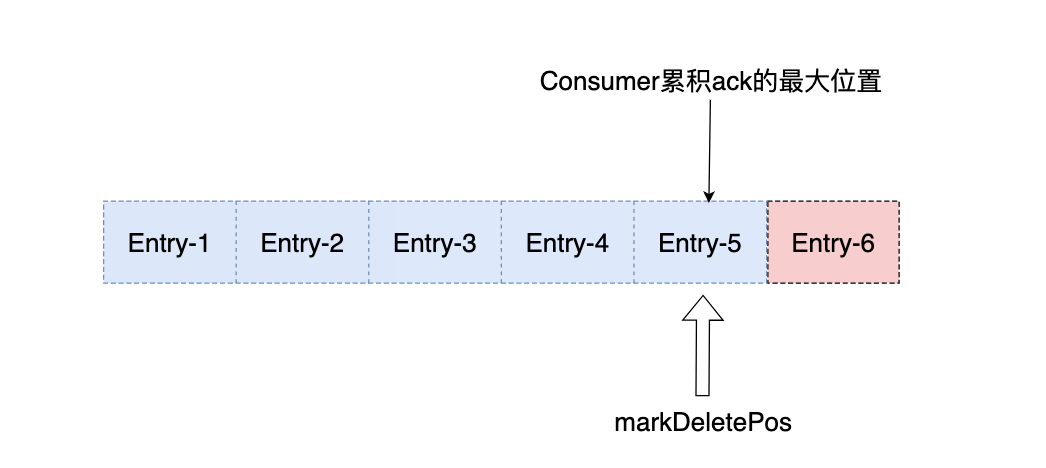
累积消息确认,只需要确认一条消息,里面包含了该次确认的最大值,游标可以往后移动多个Entry,比如:Consumer累积确认了Entry-5,则从0开始的Entry都会被确认,如下图所示:
对于share的消费模型,因为有多个消费者可以同时消费消息,因此消息的确认可能会出现空洞,空洞的形成和去除如下图所示:
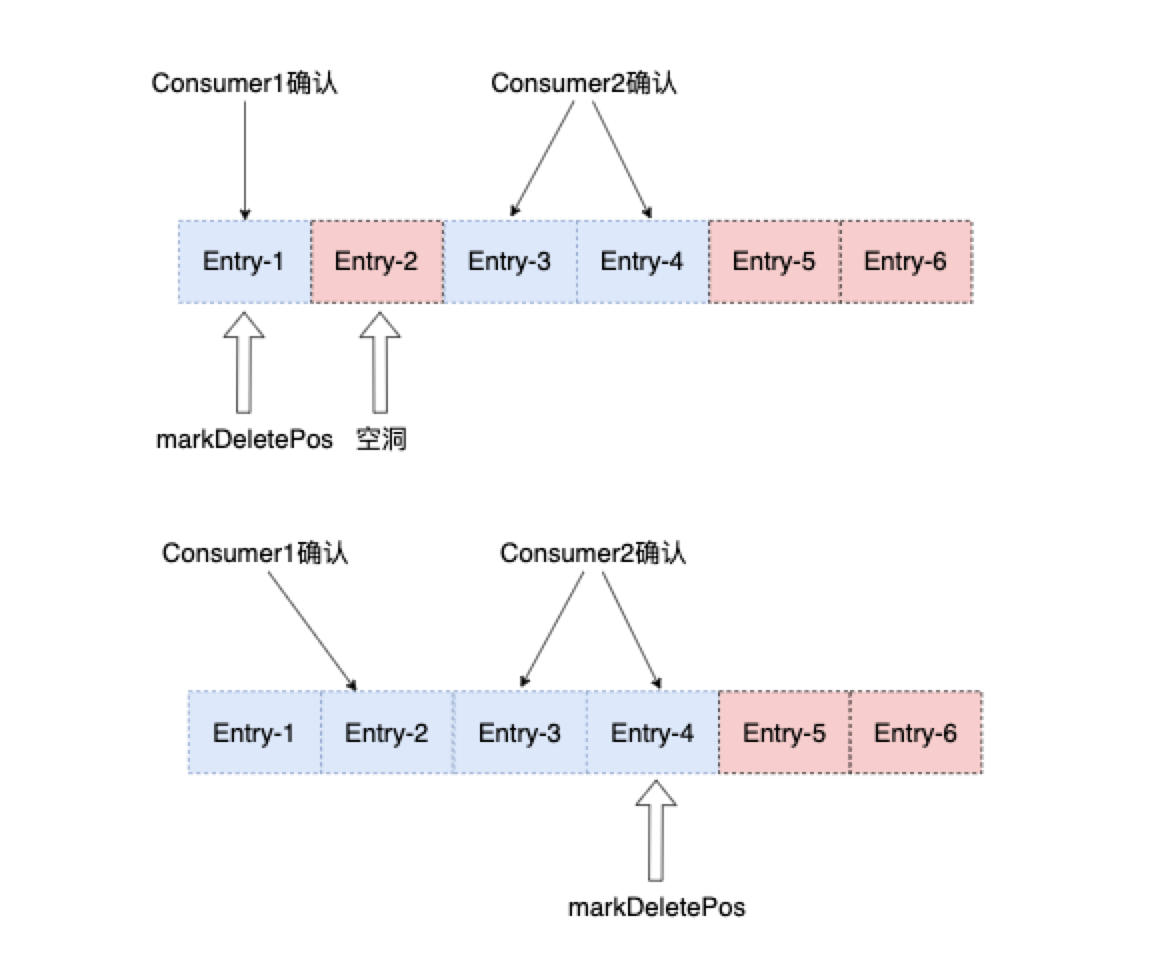
这里也解释了为什么MarkeDeletePosition指针的位置是可能发生变化,我们可以从share的消费模式中看出,消息确认是完全有可能出现空洞的,只有当前面所有的Entry都被消费并确认,MarkeDeletePosition指针才会移动。如果存在空洞,MarkeDeletePosition指针是不会往后移动的。那这个MarkeDeletePosition指针和游标是什么关系呢?首先游标(Cursor)是一个对象,里面包含了多个属性,MarkDeletePosition指针只是游标的其中一个属性。正如上面所说的Ack空洞,在游标中有另外专门的属性进行存储。假设如果不单独存储空洞,那Broker重启后,消费者只能从MarkDeletePosition开始消费,此时还是会存在重复消费的问题,例如上图中的上半部分Entry-3和Entry-4就会被重复推送给消费者。
最后来看看游标Cursor到底记录了一些什么重要的元数据,下面只列出本人认为的核心属性:
| 属性名 | 描述 |
|---|---|
| Bookkeeper | Bookkeeper Client的引用,主要用来打开Ledger,例如:读取历史数据,可以打开已经关闭的Ledger;当前Ledger已经写满,打开一个新的Ledger。 |
| MarkDeletePosition | 标记可删除的位置,在这个位置之前的所有Entry都已经被确认了,因此这个位置之前的消息都是可删除状态。 |
| PersistentMarkDeletePosition | MarkDeletePosition是异步持久化的,这个属性记录了当前已经持久化的MarkDeletePosition。当MarkDeletePosition不可用时,会以这个位置为准。这个位置会在游标Recovery时初始化,后续在持久化成功后不断更新。 |
| ReadPosition | 订阅当前读的位置,即使有多个消费者,读的位置肯定是严格有序的,只不过消息会分给不同的消费者而已。读取的位置会在游标恢复(Recovery)时初始化,消费时会不断更新 |
| LastMarkDeleteEntry | 最后被标记为删除的Entry,即MarkDeletePosition指向的Entry。 |
| CursorLedger | Cursor在Zookeeper中只会保存索引信息,具体的Ack数据会比较大,因此会保存到Bookkeeper中,这个属性持有了对应Ledger的index。 |
| IdividualDeletedMessages | 用于保存Ack的空洞信息。 |
| BatchDeletedIndexes | 用于保存批量消息中单条消息Ack信息。 |
诶?这里既然用到了CursorLedger,那说明数据都已经被保存到了Bookkeeper中了啊。看到这里聪明的你应该会有一些困惑,既然数据都保存到Bookkeeper中了,那ZooKeeper中保存的Cursor信息又有什么用呢?其实在ZooKeeper中保存的游标信息只是一些索引等轻量级信息并不包含实际的数据,索引Index信息大致是包含以下几个属性:
- 当前的CursorLedger名以及ID,用于快速定位到Bookkeeper中的Ledger;
- LastMarkDeleteEntry,最后被标记为删除的Entry信息,里面包含了LedgerId和EntryId;
- 游标最后的活动时间戳。
游标保存到ZooKeeper的timing有几个:
- 当Cursor被关闭时;
- 当发生Ledger切换导致cursorLedger变化时;
- 当持久化空洞数据到Bookkeeper失败并尝试持久化空洞数据到ZooKeeper时。
其实可以把ZooKeeper中的游标信息看作检查点(Check Point)或者索引快照(IndexSnapshot),当恢复数据时,会先从ZooKeeper中恢复元数据,获取到Bookkeeper Ledger信息,然后再通过Ledger恢复最新的LastMarkDeleteEntry位置和空洞信息。既然游标并不是实时往ZooKeeper中写入数据的,那Pulsar是如何保证消费位置不丢失的呢?其实Bookkeeper中的一个Ledge是能写很多的Entry的,所以高频的保存操作都由Bookkeeper来承担了,换句话说就是专业的事情交给专业的人,ZooKeeper只负责存储低频的轻量级索引更新,至于更新的timing上面已经讲过了。
消息空洞
什么是消息空洞?这是我们上面说到的一个高频词汇了,在游标Object中,使用了一个叫IndividualDeletedMessages的容器来存储所有的空洞信息。Broker中直接使用了Guava Range这个库来实现空洞的存储。看如下一个例子,假设在Ledger-5中的空洞如下:

那么就会用如下的区间表达方式来存储空洞信息 : [ (5:-1, 5:5] , (5:6, 5:7] ]
使用区间表达的好处就是可以用很少的区间数来表示整个Ledger的空洞情况,而不需要每个Entry都记录(但是这并不是绝对的,有一些特殊的情况即便使用区间也是会效率低下的)。当某个范围都已经被消费且确认了,就会出现两个区间merge为一个区间,这都是Guava Range自动支持的能力。如果从当前MarkDeletePosition指针的位置到后面某个Entry为止,都连成了一个连续的区间,那么MarkDeletePosition指针就可以往后移动了,直到后面的某个Entry为止。
虽然记录了这些消息空洞的信息,但是具体是如使用这些信息来避免消息重复消费的呢?
当Broker从Ledger中读取到消息后,会进入一个清洗阶段,如:过滤掉延迟消息等等。在这个阶段,Broker会遍历所有消息,看消息是否存在于Range里,如果存在,则说明已经被确认过了,这条消息会被过滤掉,不再推送给客户端。Guava Range提供了Contains接口,可以快速查看某个位置是否落在区间里。这种Entry需要被过滤的场景,基本上只会出现在Broker重启后,此时游标信息刚恢复。当ReadPosition超过了这段空洞的位置时,就不会出现读到重复消息要被过滤的情况了。
那么现在来看看IndividualDeletedMessages这个容器的实现原理:
IndividualDeletedMessages 的类型是LongPairRangeSet,默认实现是DefaultRangeSet,是一个基于Google Guava Range包装的实现类。另外还有一个Pulsar自己实现的优化版:ConcurrentOpenLongPairRangeSet,这一优化版的实现就是为了解决上面我们说过的那种特殊情况。优化版的RangeSet和Guava Range的存储方式有些不一样,Guava Range使用区间来记录数据,优化版RangeSet对外提供的接口也是Range,但是内部使用了BitSet来记录每个Entry是否被确认。
优化版RangeSet在空洞较多的情况下对内存更加友好。来看下上面说的那种特殊,比如有1000W的消息已被拉取,但是只有500W的消息被Ack,并且是隔条进行的Ack,这样的话就会出现50W个间隔型的空洞。此时如果还是使用Range就会非常麻烦毫无优势可言,会有500W个Range对象,看下图。而优化版的RangeSet还是使用了BitMap,每个Ack只占一位一bit而已,1kb即可表现8192个空洞。
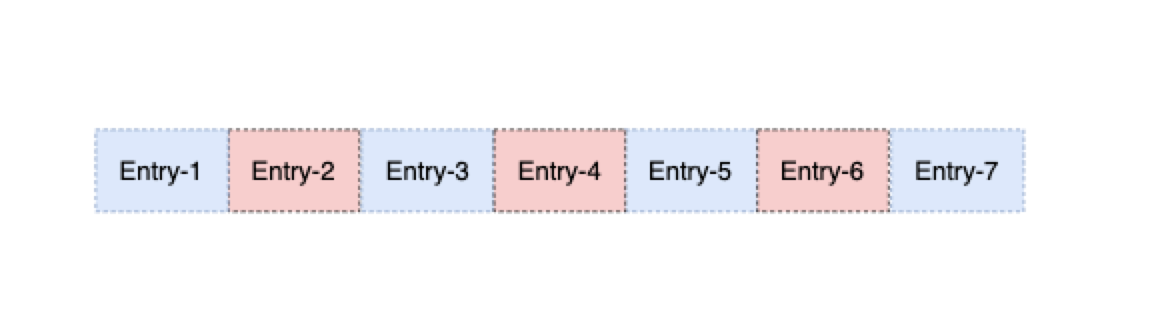
我们可在broker.conf中,通过配置项managedLedgerUnackedRangesOpenCacheSetEnabled=true来开启使用优化版的RangeSet实现。所以,如果整个集群的subscription数比较多,游标对象的数据量是不容小视的。来回顾一下Pulsar的实现方式,MetaDataStore中只保存了游标的索引信息,即记录了游标的具体数据是存储在bk上的哪个Ledger中。真正的游标数据会通过上面介绍的CursorLedger写入到Bookkeeper中持久化。整个游标对象会被写入到一个Entry中,其Pb的定义如下:
1 | message PositionInfo { |
看到这里,其实Batch消息中单条消息确认的实现也清晰了,BatchDeletedIndexes是一个ConcurrentSkipListMap,Key为一个Position对象,对象里面包含了LedgerId和EntryId。Value是一个BitSet,记录了这个Batch里面哪些消息已经被确认。batchedEntryDeletionIndexInfo会和单条消息的空洞一起放在同一个对象(PositionInfo)中,最后持久化到Bookkeeper。
空洞数据如果写入Bookkeeper失败了,Pulsar还会尝试往ZooKeeper中保存,和索引信息一起保存。但是ZooKeeper毕竟不是专业的存储媒介所以并不会保存所有的数据,而是努力的保存一小部分,尽可能的让客户端不出现重复消费。我们可以通过broker.conf中的配置项来决定最多持久化多少数据到ZooKeeper,配置项名为:managedLedgerMaxUnackedRangesToPersistInZooKeeper,默认值是1000,最后提一点就是如果在实际的使用场景中有对幂等性强要求的还是建议在消费端做好校验。
消息空洞管理的优化方案
上文介绍的空洞存储方案看似完美,但是在海量未确认消息的场景下还是会出现一些问题的。首先是大量的订阅会让游标数量暴增,导致Broker内存的占用过大。其次,有很多空洞其实是根本是不会发生变化的,现在每次都要保存全量的空洞数据。最后,虽然优化版RangeSet在内存中使用了BitSet来存储,但是实际存储在Bookkeeper中的数据MessageRange,还是一个个由LedgerId和EntryId组成的对象,每个MessageRange占用16字节。当空洞数量比较多时,总体体积会超过5MB,而现在Bookkeeper能写入的单个Entry大小上限是5MB,如果超过这个阈值就会出现空洞信息持久化失败的情况。
目前新的解决方案中主要使用LRU+分段存储的方式来解决上述问题。由于游标中空洞信息数据量可能会很大,因此内存中只保存少量热点区间,通过LRU算法来切换冷热数据,从而进一步压缩内存的使用率。分段存储主要是把空洞信息存储到不同的Entry中去,这样能避免超过一个Entry最大消息5MB的限制。
如果我们把空洞信息拆分为多个Entry来存储,首先面临的问题是索引。因为使用单个Entry记录时,只需要读取Ledger中最后一个Entry即可,而拆分为多个Entry后,我们不知道要读取多少个Entry。因此,新方案中引入了Marker,如下图所示:
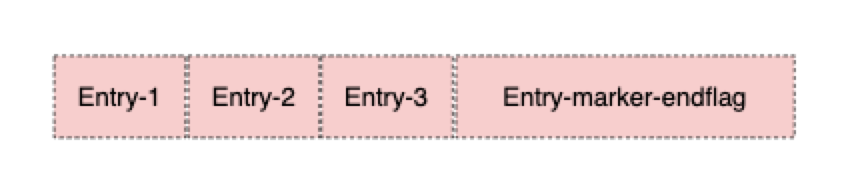
当所有的Entry保存完成后,插入一个Marker,Marker是一个特殊的Entry,记录了当前所有拆分存储的Entry,这里我们可以联想一下之前我介绍过的tlv解析。当数据恢复时,从后往前读,先读出索引,然后再根据索引读取所有的Entry。
由于存储涉及到多个Entry,因此需要保证原子性,只要最后一个Entry读出来不是Marker,则说明上次的保存没有完成就中断了,会继续往前读,直到找到一个完整的Marker。
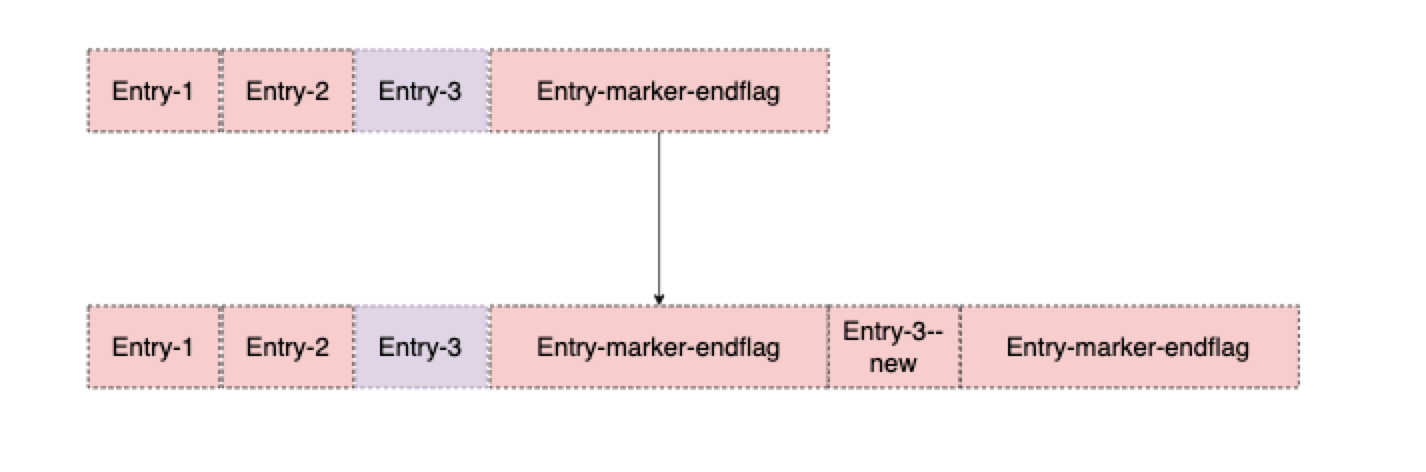
空洞信息的存储,也不需要每次全量了。以Ledger为单位,记录每个Ledger下的数据是否有修改过,如果空洞数据被修改过会被标识为脏数据,存储时只会保存有脏数据的部分,然后修改Marker中的索引。
如下Entry-3中存储的空洞信息有修改,则Entry-3会被标记为脏数据,下次存储时,只需要存储一个Entry-3–new,再存储一个Marker即可。只有当整个Ledger写满的情况下,才会触发Marker中所有Entry复制到新Ledger的情况。如下图所示:
ManagedLedger在内存中通过LinkedHashMap实现了一个LRU链表,会有线程定时检查空洞信息的内存占用是否已经达到阈值,如果达到了阈值则需要进行LRU换出,切换以Ledger为单位,把最少使用的数据从Map中移除。LRU数据的换入是同步的,当添加或者调用Contains时,发现Marker中存在这个Ledger的索引,但是内存中没有对应的数据,则会触发同步数据的加载。异步换出和同步换入,主要是为了让数据尽量在内存中多待一会,避免出现频繁的换入换出。不过话说回来,这是Pulsar给我们提供的基建功能,非常优秀,但是在实际使用上其实是可以避免这样大规模的消息空洞出现的,下面在实践篇中也会聊到。
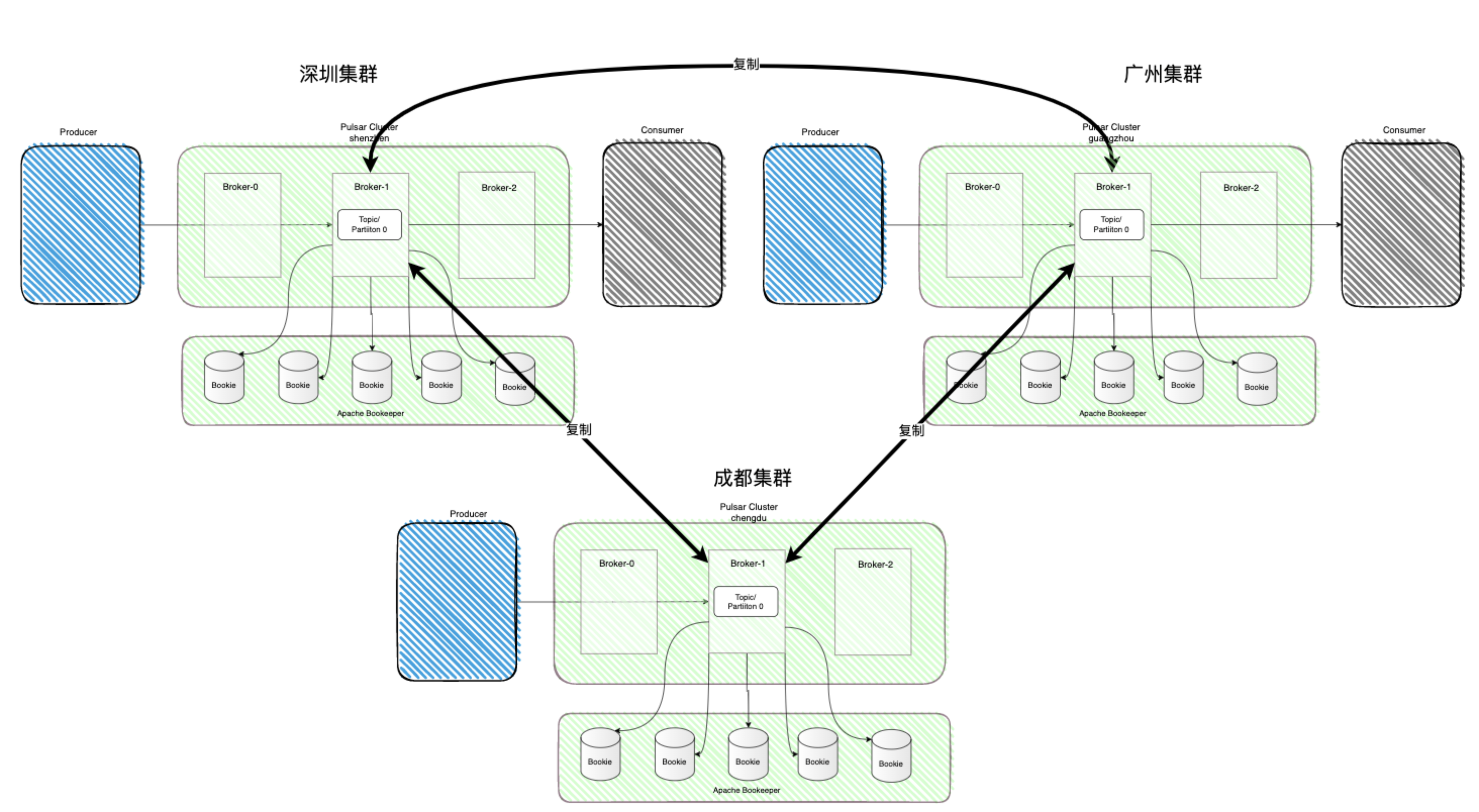
跨地域复制
最后就是跨地域复制功能了,它是Pulsar提供的基础功能,不同地域不同Topic之间通过可配的方式实现了数据互通,是一种全连接的异步复制,可以满足多个数据中心数据同步的使用场景。如下图所示,当在成都集群生产了一条消息,该消息会立即复制到深圳和广州集群,这样深圳广州集群的消费者不仅可以消费到自己集群生产者生产的消息,还可以消费到成都集群生产者生产的消息。
总结
写到这里,Pulsar的原理基本上就介绍完了,相信诸位对Pulsar已经有了一个全面且清晰的认识了,理解其原理对于我们用好Pulsar是十分重要的,希望这篇文章可以帮助到你,后面还有一章实践篇,主要就是本人最近在实际使用中的一些踩坑与总结~非常硬核,敬请期待……
Slogan : 香说当你遇事不顺时要相信一句话,一些都是最好的安排~
