前言
上一篇文章对Pulsar的topic和分区做了介绍,这一篇我们就来对消息存储原理和ID规则来进行一下介绍,在本篇介绍中可能会出现一些让你非常困惑的词汇。不过不要紧我都会一一来进行解释
消息 ID 生成规则
在 Pulsar 中,每条消息都有属于的自己的唯一 ID(即 MessageID),MessageID 由四部分组成:ledgerId:entryID:partition-index:batch-index。其中:
- partition-index:指分区的编号,在非分区 topic 的时候为 -1。
- batch-index:在非批量消息的时候为 -1。
消息 ID 的生成规则由 Pulsar 的消息存储机制决定,Pulsar 中消息存储原理图如下:
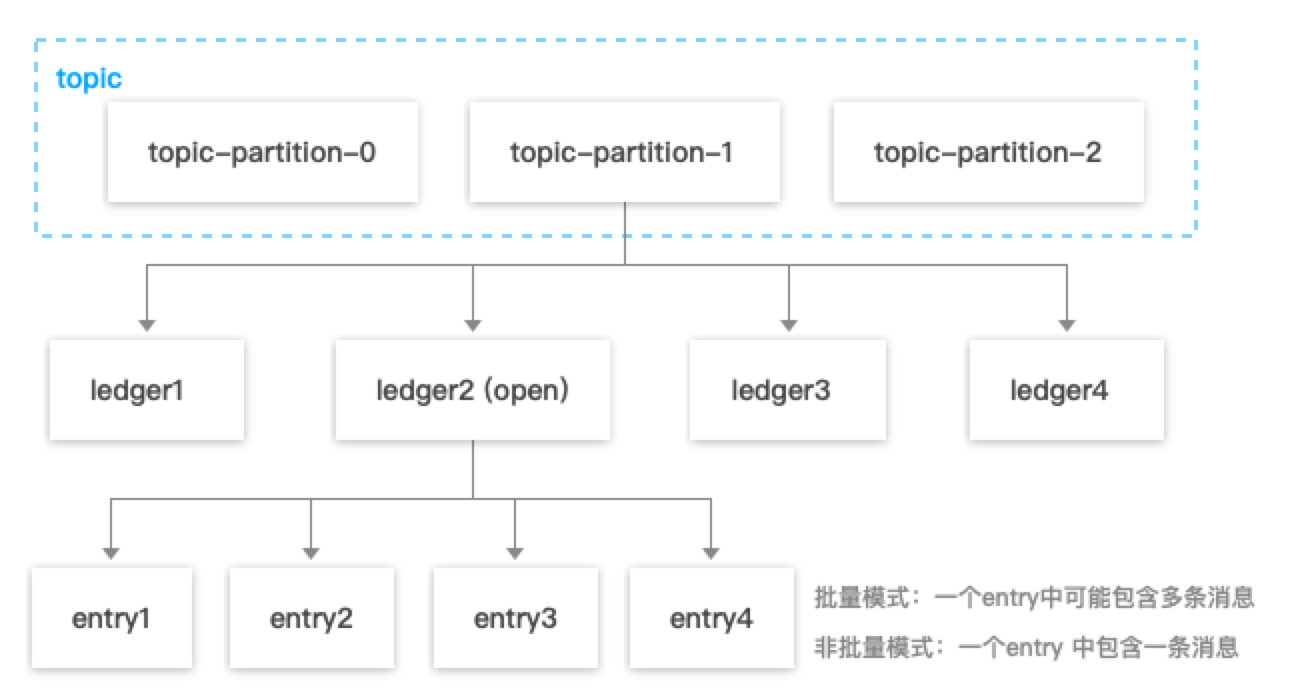
如上图所示,在 Pulsar中,一个 Topic 的每一个分区会对应一系列的 ledger,其中只有一个 ledger 处于 open 状态即可写状态,而每个 ledger 只会存储与之对应的分区下的消息。
Pulsar 在存储消息时,会先找到当前分区使用的 ledger ,然后生成当前消息对应的 entry ID,entry ID 在同一个 ledger 内是递增的。每个 ledger 存在的时长或保存的 entry 个数超过阈值后会进行切换,新的消息会存储到同一个 partition 中的下一个 ledger 中。
- 批量生产消息情况下,一个 entry 中可能包含多条消息。
- 非批量生产的情况下,一个 entry 中包含一条消息(producer 端可以配置这个参数,默认是批量的)。
Ledger 只是一个逻辑概念,是数据的一种逻辑组装维度,并没有对应的实体。而 bookie 只会按照 entry 维度进行写入、查找、获取。
分片机制详解:Legder 和 Entry
Pulsar 中的消息数据以 ledger 的形式存储在 BookKeeper 集群的 bookie 存储节点上。Ledger 是一个只追加的数据结构,并且只有一个写入器,这个写入器负责多个 bookie 的写入。Ledger 的条目会被复制到多个 bookie 中,同时会写入相关的数据来保证数据的一致性。
BookKeeper 需要保存的数据包括:
- Journals
- journals 文件里存储了 BookKeeper 的事务日志,在任何针对 ledger 的更新发生前,都会先将这个更新的描述信息持久化到这个 journal 文件中。
- BookKeeper 提供有单独的 sync 线程根据当前 journal 文件的大小来作 journal 文件的 rolling。
- EntryLogFile
- 存储真正数据的文件,来自不同 ledger 的 entry 数据先缓存在内存buffer中,然后批量flush到EntryLogFile中。
- 默认情况下,所有ledger的数据都是聚合然后顺序写入到同一个EntryLog文件中,避免磁盘随机写。
- Index 文件
- 所有 Ledger 的 entry 数据都写入相同的 EntryLog 文件中,为了加速数据读取,会作 ledgerId + entryId 到文件 offset 的映射,这个映射会缓存在内存中,称为 IndexCache。
- IndexCache 容量达到上限时,会被 sync 线程 flush 到磁盘中。
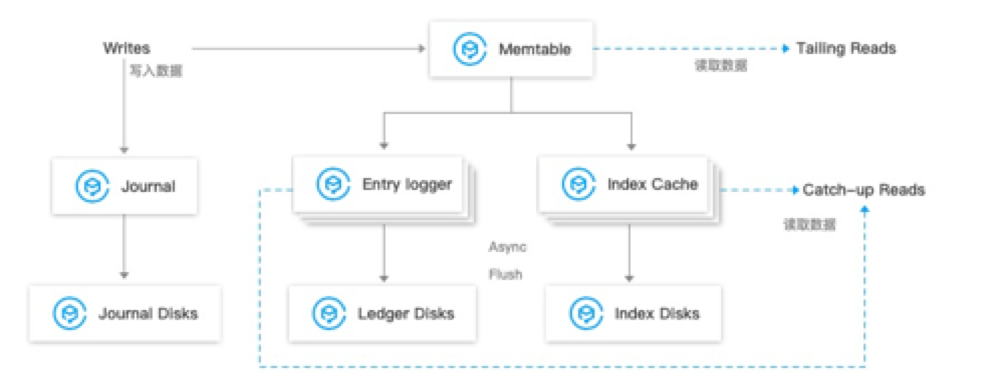
刚开始看到这里的时候我是有点懵逼的,这都是些啥啊,但是后面仔细思考下,这个设计似乎和mysql的底层原理几乎一致,Journals相当于redolog,EntryLogFile+Index相当于bufferpool。还不明白那就接着看下面的介绍:
Entry 数据写入
- 数据首先会同时写入 Journal(写入 Journal 的数据会实时落到磁盘)和 Memtable(读写缓存)。
- 写入 Memtable 之后,对写入请求进行响应。
- Memtable 写满之后,会 flush 到 Entry Logger 和 Index cache,Entry Logger 中保存数据,Index cache 中保存数据的索引信息,
- 后台线程将 Entry Logger 和 Index cache 数据落到磁盘。
Entry 数据读取
- Tailing read 请求:直接从 Memtable 中读取 Entry。
- Catch-up read(滞后消费)请求:先读取 Index信息,然后索引从 Entry Logger 文件读取 Entry。
数据一致性保证:LastLogMark
- 写入的 EntryLog 和 Index 都是先缓存在内存中,再根据一定的条件周期性的 flush 到磁盘,这就造成了从内存到持久化到磁盘的时间间隔,如果在这间隔内 BookKeeper 进程崩溃,在重启后,我们需要根据 journal 文件内容来恢复,这个 LastLogMark 就记录了从 journal 中什么位置开始恢复。
- 它其实是存在内存中,当 IndexCache 被 flush 到磁盘后其值会被更新,LastLogMark 也会周期性持久化到磁盘文件,供 Bookkeeper 进程启动时读取来从 journal 中恢复。
- LastLogMark 一旦被持久化到磁盘,即意味着在其之前的 Index 和 EntryLog 都已经被持久化到了磁盘,那么 journal 在这 LastLogMark 之前的数据都可以被清除了。
总结
