前言
本人最近正在重构一个vdc(virus detect center)系统,为了将旧系统解耦我们将原系统拆分成了很多子系统,系统之间通过mq进行交互,在这之前本人对kafka已经是有些许了解,但是这次小组决定使用pulsar来替代kafka,那么究竟pulsar有什么好,它较kafka到底有什么优势,本人接下来的一个系列篇章就会对pulsar来进行介绍,同时也会讲解实际使用中的一些用法与问题,本系列文章的前提是假定大家对kafka都是一定了解的。
Apache Pulsar 架构
Apache Pulsar 是一个发布-订阅模型的消息系统,由 Broker、Apache BookKeeper、Producer、Consumer 等组件组成。我们知道传统mq的组成是没有Apache BookKeeper这一组件的,那么这个Apache BookKeeper究竟是何方神圣,后面我们会详细说一说
先看一张整体的结构图:
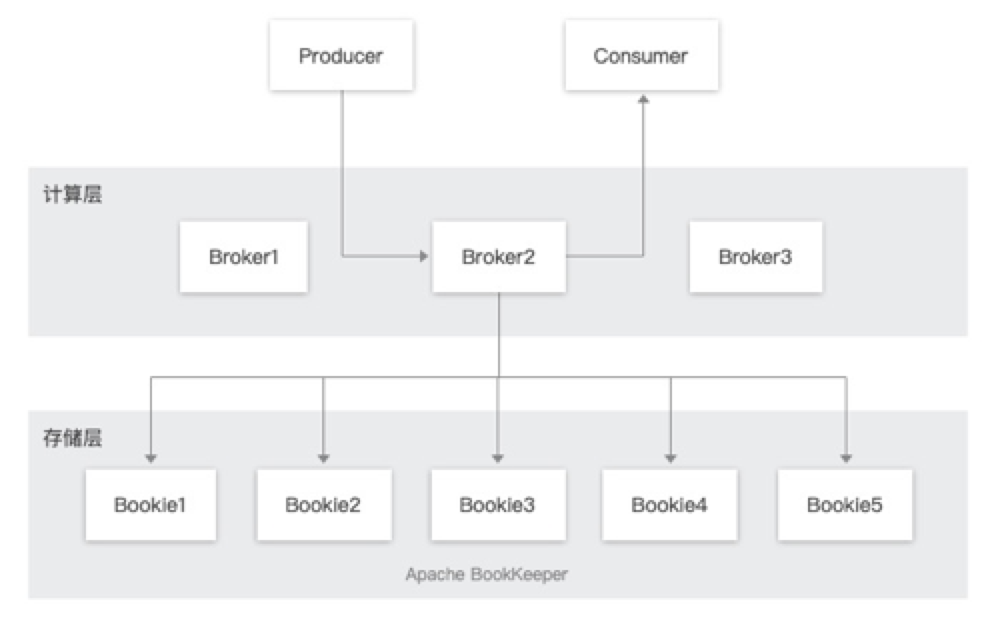
- Producer : 消息的生产者,负责发布消息到 Topic。
- Consumer:消息的消费者,负责从 Topic 订阅消息。
- Broker:无状态服务层,负责接收和传递消息,集群负载均衡等工作,Broker 不会持久化保存元数据,因此可以快速的上、下线。
- Apache BookKeeper:有状态持久层,由一组 Bookie 存储节点组成,可以持久化地存储消息。
了解kafka的朋友相信一眼就能看出一些异样,那就是kafka的存储其实就是放在broker上面的,也就是说存储与计算实际上是一体的,而从上图可知 Apache Pulsar 在架构设计上采用了计算与存储分离的模式,消息发布和订阅相关的计算逻辑在 Broker 中完成,数据存储在 Apache BookKeeper 集群的 Bookie 节点上。
Topic 与分区
Topic(主题)是某一种分类的名字,消息在 Topic 中可以被存储和发布。生产者往 Topic 中写消息,消费者从 Topic 中读消息。
Pulsar 的 Topic 分为 Partitioned Topic 和 Non-Partitioned Topic 两类,Non-Partitioned Topic 可以理解为一个分区数为1的 Topic。实际上在 Pulsar 中,Topic 是一个虚拟的概念,创建一个3分区的 Topic,实际上是创建了3个“分区Topic”,发给这个 Topic 的消息会被发往这个 Topic 对应的多个 “分区Topic”。
例如:生产者发送消息给一个分区数为3,名为my-topic的 Topic,在数据流向上是均匀或者按一定规则(如果指定了key)发送给了 my-topic-partition-0、my-topic-partition-1 和 my-topic-partition-2 三个“分区 Topic”。
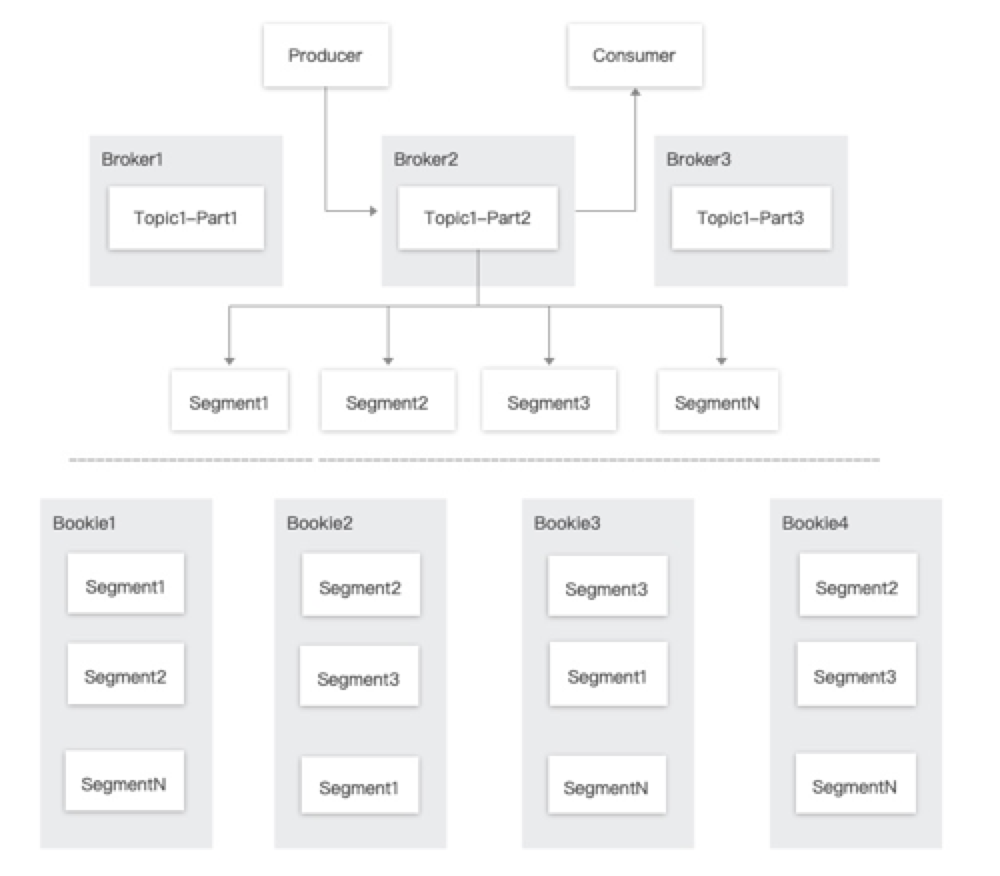
分区 Topic 做数据持久化时,分区是逻辑上的概念,实际存储的单位是分片(Segment)的。
如下图所示,分区 Topic1-Part2 的数据由N个 Segment 组成, 每个 Segment 均匀分布并存储在 Apache BookKeeper 群集中的多个 Bookie 节点中, 每个 Segment 具有3个副本。
物理分区与逻辑分区
逻辑分区和物理分区对比如下:
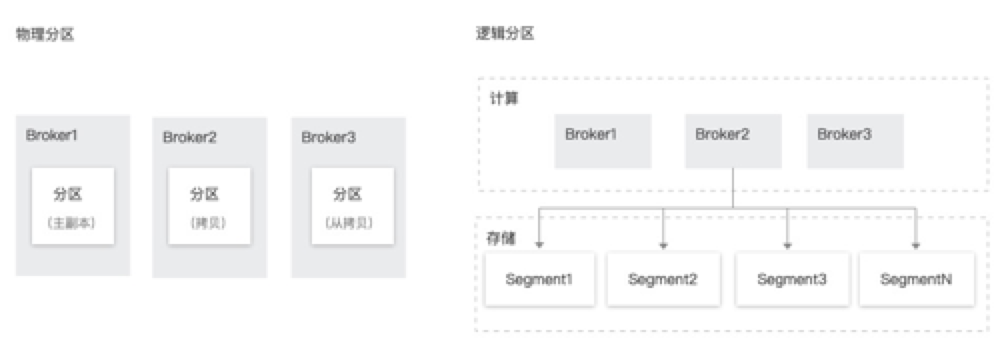
物理分区:计算与存储耦合,容错需要拷贝物理分区,扩容需要迁移物理分区来达到负载均衡。
逻辑分区:物理“分片”,计算层与存储层隔离,这种结构使得 Apache Pulsar 具备以下优点。
- Broker 和 Bookie 相互独立,方便实现独立的扩展以及独立的容错。
- Broker 无状态,便于快速上、下线,更加适合于云原生场景。
- 分区存储不受限于单个节点存储容量。
- 分区数据分布均匀,单个分区数据量突出不会使整个集群出现木桶效应。
- 存储不足扩容时,能迅速利用新增节点平摊存储负载。
总结
