前言
本人前不久稍稍改进了一个cdkey系统,来总结下是如何设计一个cdkey(兑换码)系统的,本文打算从以下三个方面来说。
- cdkey兑换
- 如何生成cdkey以及如何存储
- 如何保证高可用
cdkey兑换
cdkey本身只是一种推广售卖方式,其实不用也是可以的,不过市面上的商品一般除了正常的收费购买之外一定会伴随有cdkey售卖这样的方式。一个cdkey就对应着一个具体的商品,这也意味着cdkey是需要与商品以及订进行绑定的,举个例子,类似这样的一串字符串XXX3XXXNLMX1YEXXX就是cdkey的一个样式,是一个36进制构成的16位表达式,一般先由系统提前生成好然后下发出去售卖或者活动赠送等,兑换的时候做一些校验工作然后是生成订单流程,订单流程走完之后最后将订单号与cdkey绑定并将其状态更改成已兑换。流程如下图:
流程图因涉及到公司的业务流转 不方便在此贴出
如何生成cdkey以及如何存储
上一节提到目前系统的cdkey是一个36进制的16位表达式,针对36进制我们可以预先定义一个数组:
1 | myVal = []string{"A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M", "N", "O", "P","Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z","0", "1", "2", "3", "4", "5", "6", "7", "8", "9"} |
当然为了安全我们也可以将上述的数组顺序随意打乱,这种方式在上一篇短链系统设计的时候已经用过一次了,只不过短链用的是64进制而已。我们也可以使用64进制来降低cdkey生成时的碰撞率,不过就cdkey而言为了美观一般就不掺杂小写字母了。本人目前的需求是需要支持大批量cdk申请的,单批次申请需要支持10w,所以我这边cdkey的生成实际是按批次生成的,这样的好处就是可以减少与数据库的网络IO,每次生成一批cdkey然后去数据库校验是否存在,存在了就重试生成一批新cdkey再校验,直到校验不存在就插入数据库然后生成下一批,反复执行直到申请数量全部生成完毕。
总体流程图如下:
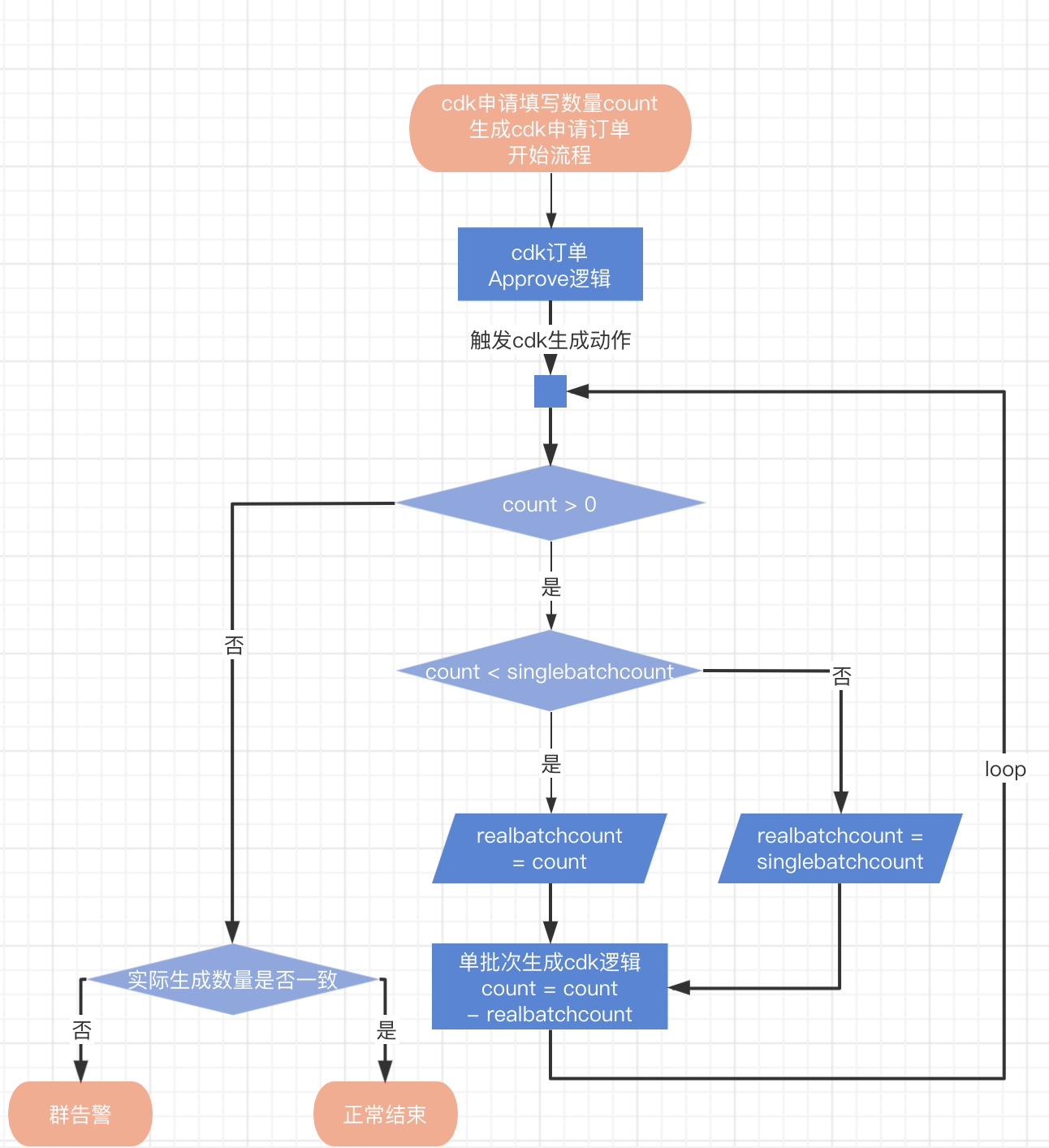
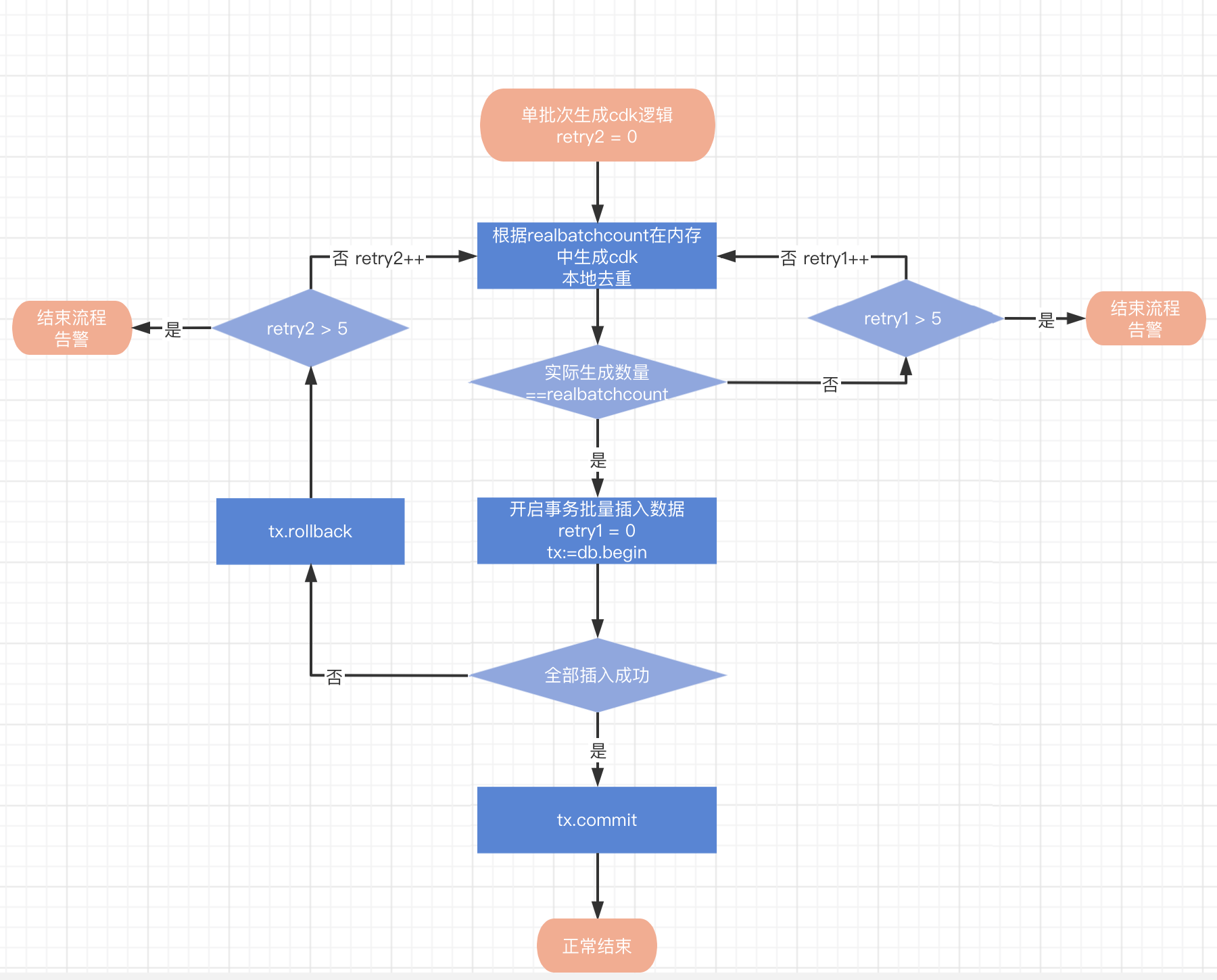
接下来是单批次生成cdk详细逻辑:
给出表设计方案 :
下面的表中很多字段都是与具体业务相关的,不必过于关心,但是核心的字段在一个cdk系统中基本上都是不变的。
1 | //因为表设计也有相关敏感信息不方便在此处贴出具体字段 |
如何保证高可用
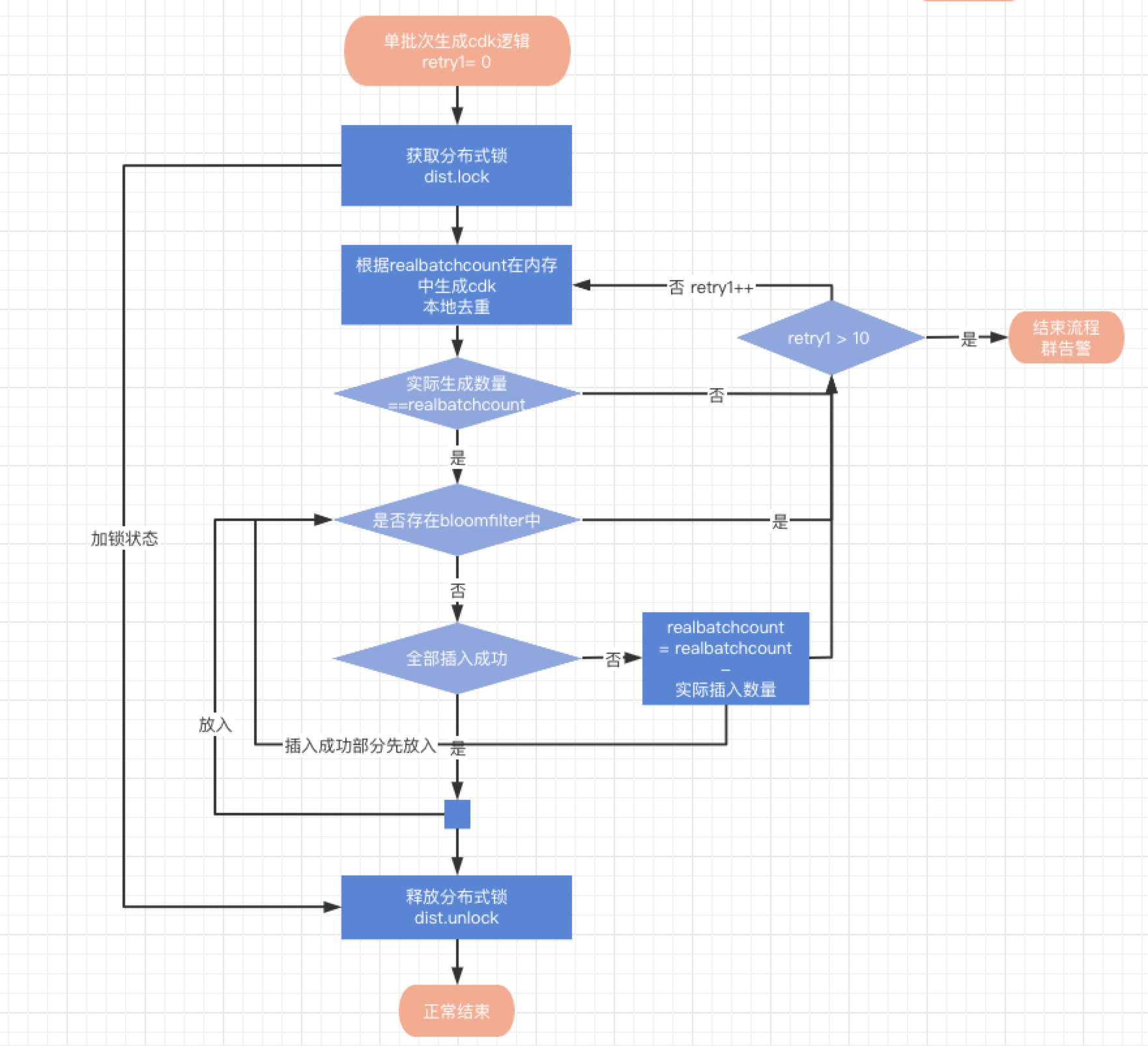
一般来说通过集群部署可解决系统高可用问题,但是集群部署就会导致新的问题,可能两个服务节点同时工作产生的cdkey就有可能会出现交集本地去重并不能解决问题,这里我列出了两种方案来解决这个问题,就当前情况而言本人采用了第一种方案:
方案一:通过数据库自身来解决该问题
上一节介绍的方案就是了,通过数据库校验 + 事务 + 重试来解决
方案二:通过分布式锁+bloomfilter来解决这个问题
见方案设计图:
总结
本文对cdk系统设计方案作了一点总结,整体的思路就是要减少碰撞,保证申请数量与实际生成数量一致,并且要防止一次性提交数据量过大,具体最后的高可用方案哪种更合适还是依据实际情况再做定夺为佳。
