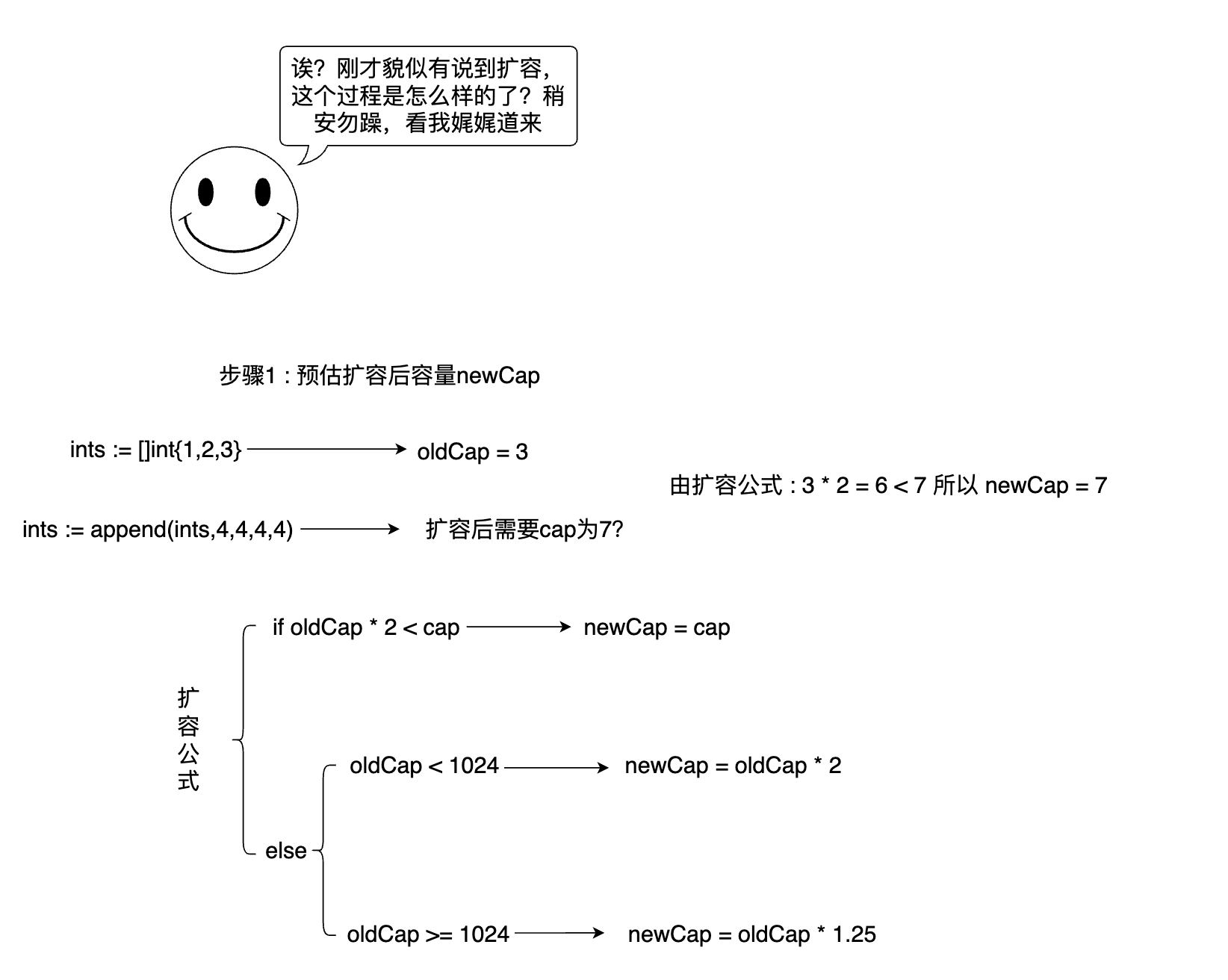
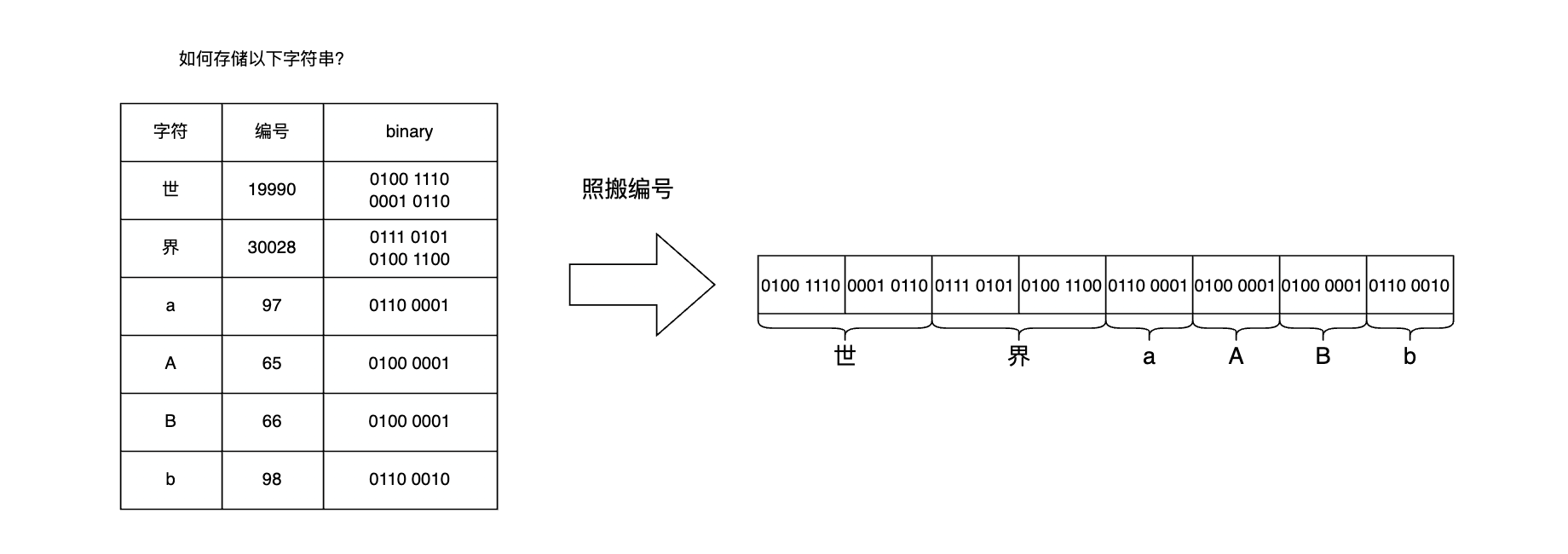
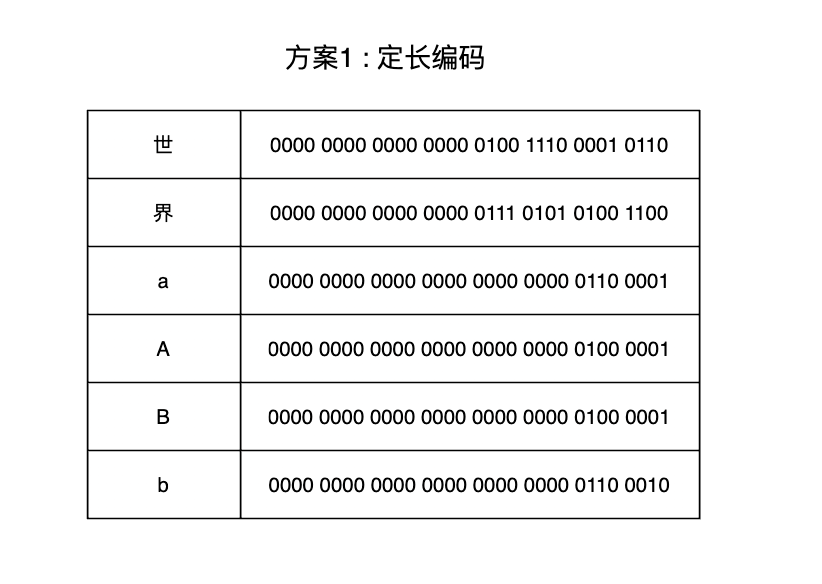
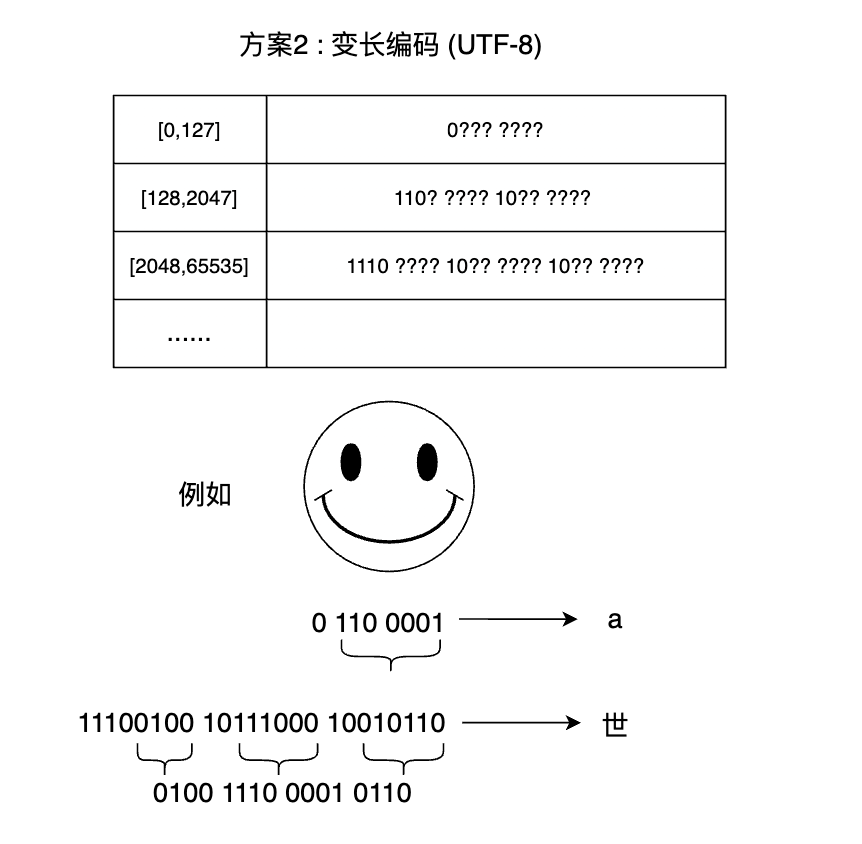
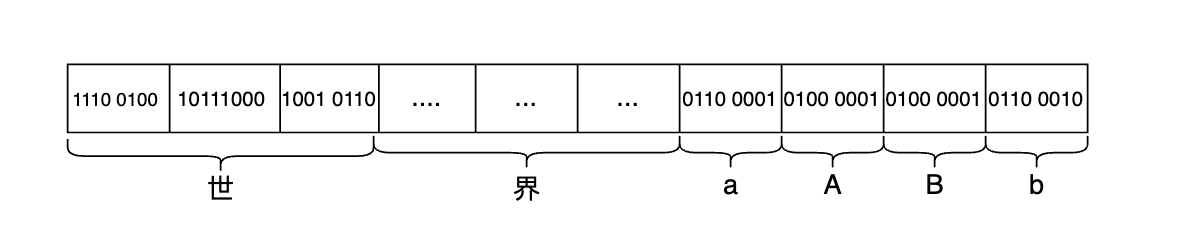
前言
上一篇文章介绍了Pulsar的相关理论知识,今天就来总结下实践过程中Pulsar的相关注意事项吧
Pulsar小总结
基础架构
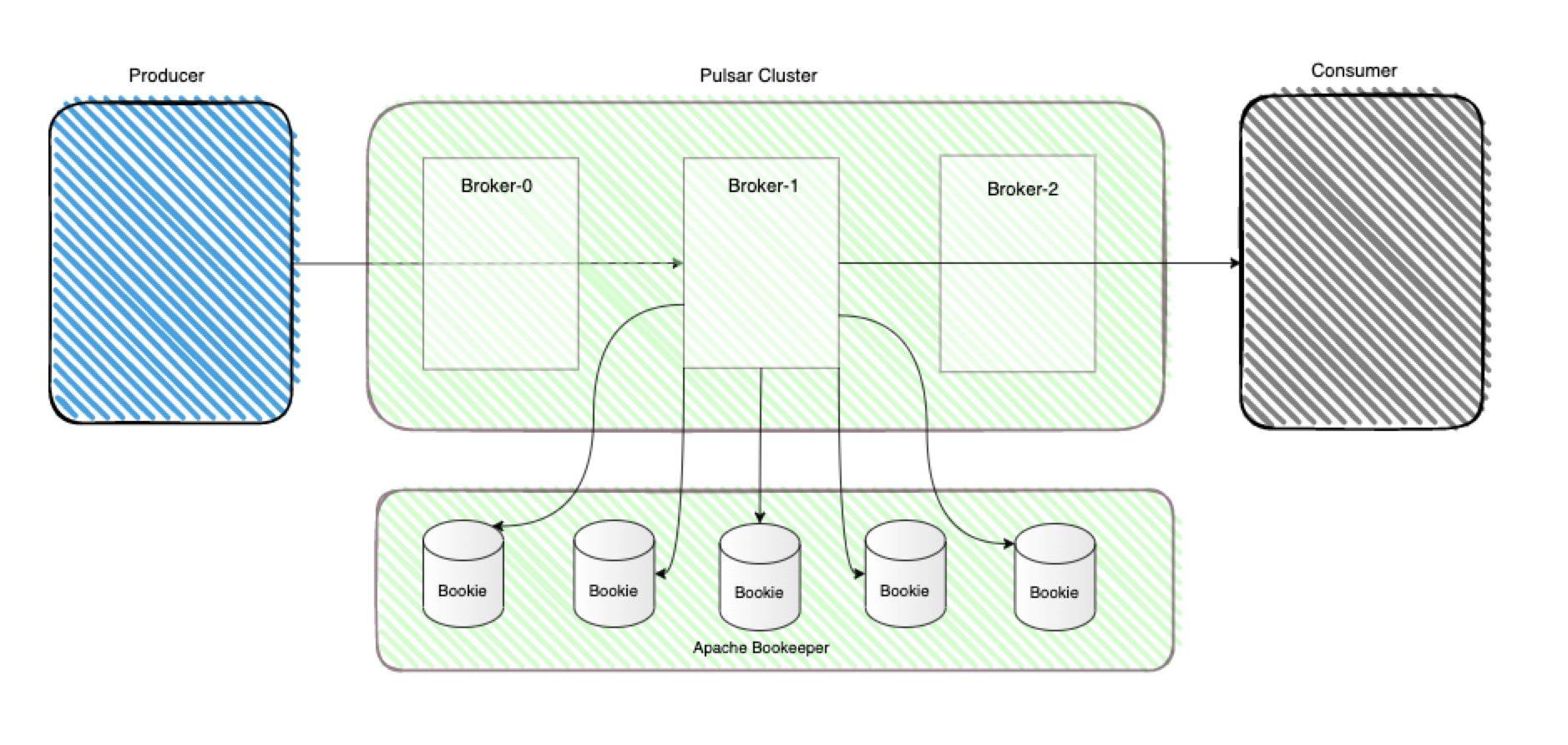
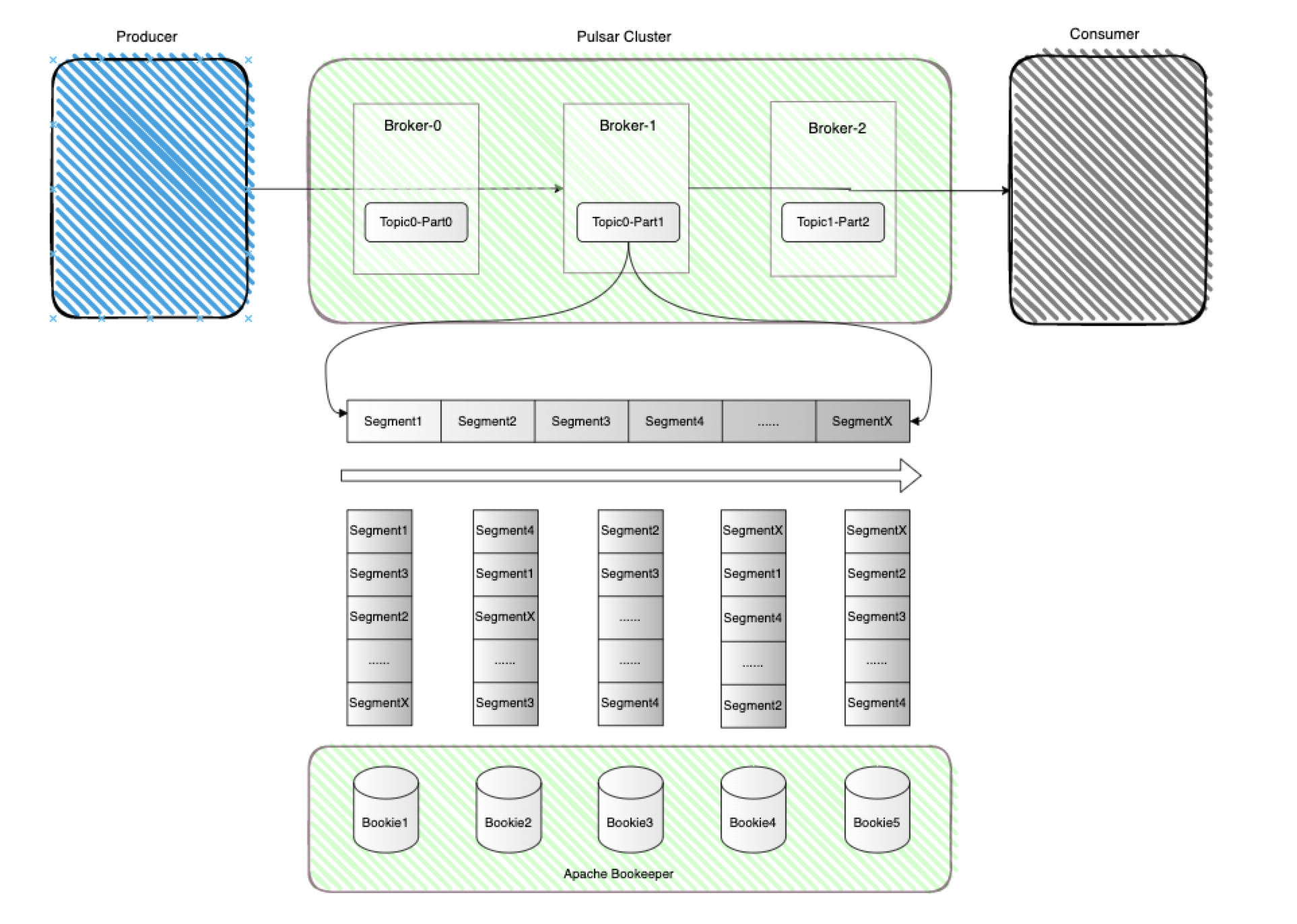
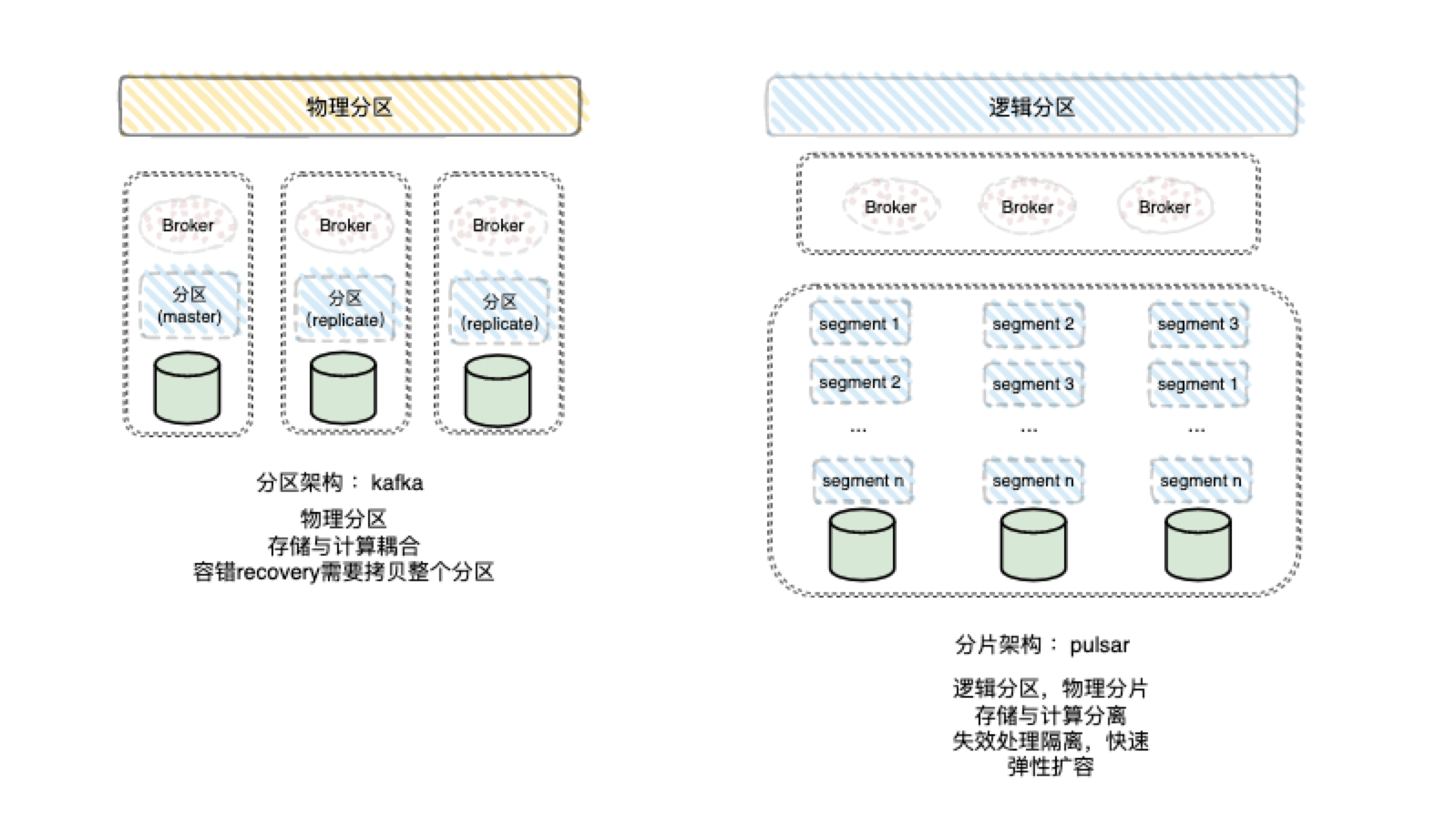
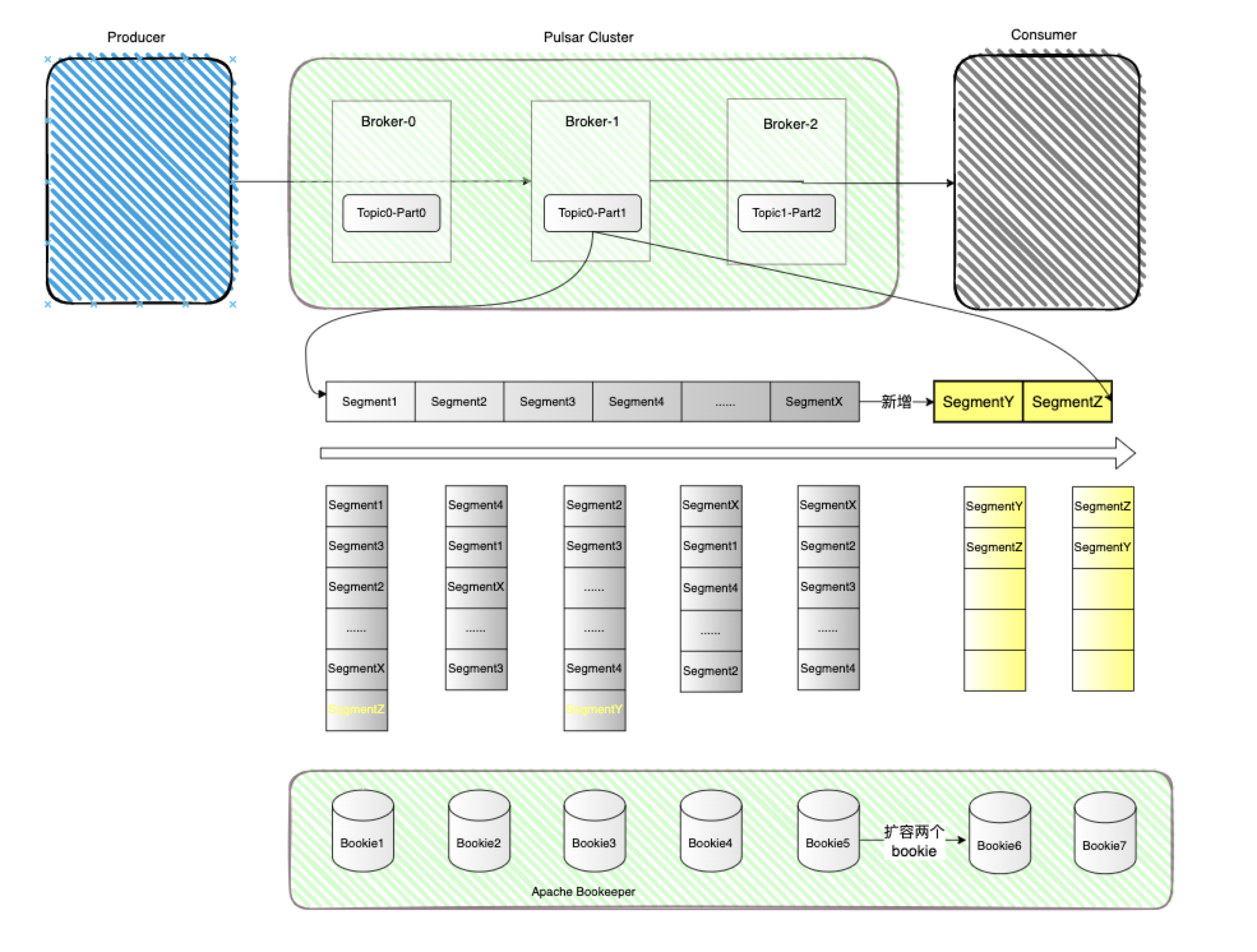
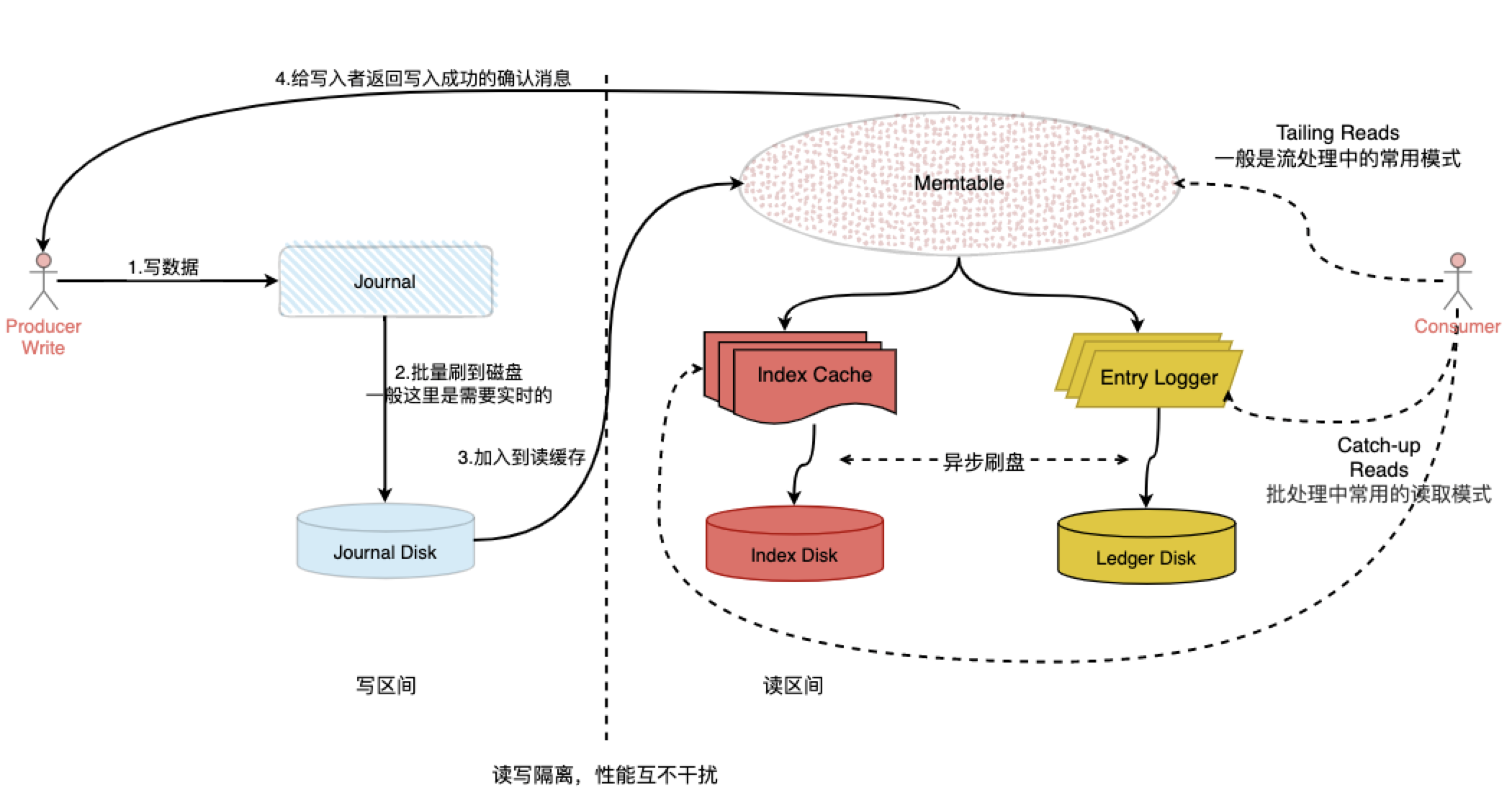
Apache Pulsar 当然也是一款MQ,它是Pub/Sub型的消息系统,但是从架构设计上来说与前文介绍的kafka是完全不同的,Pulsar在结构上将计算与存储完全分离。先看下图来初步认识下Pulsar的整体架构:
首先来总结一下Pulsar较其他消息队列的优势,为什么在众多MQ当中,我们选择了Pulsar:
1、Pulsar支持多租户,按Namespace进行级别进行资源隔离,搭建公司级集群更加方便;
2、计算与存储隔离,无状态broker可以更好的动态扩所容,天赋云原生;
3、消费模式同时支持流模式(kafka)和队列模式(rabbitmq),选择性更强;
4、读写分离,支持百万级topic(tail-read And catch-up-read),更低的端到端时延;
5、无Rebalance;
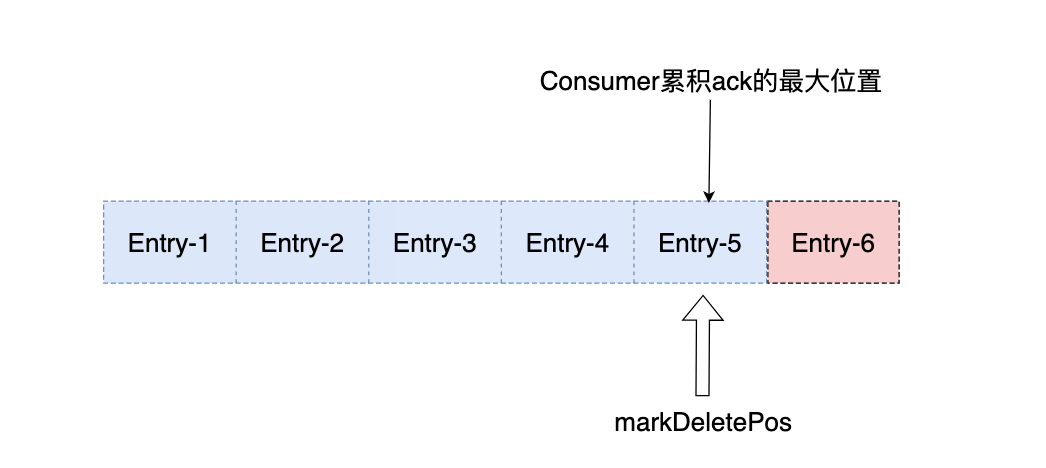
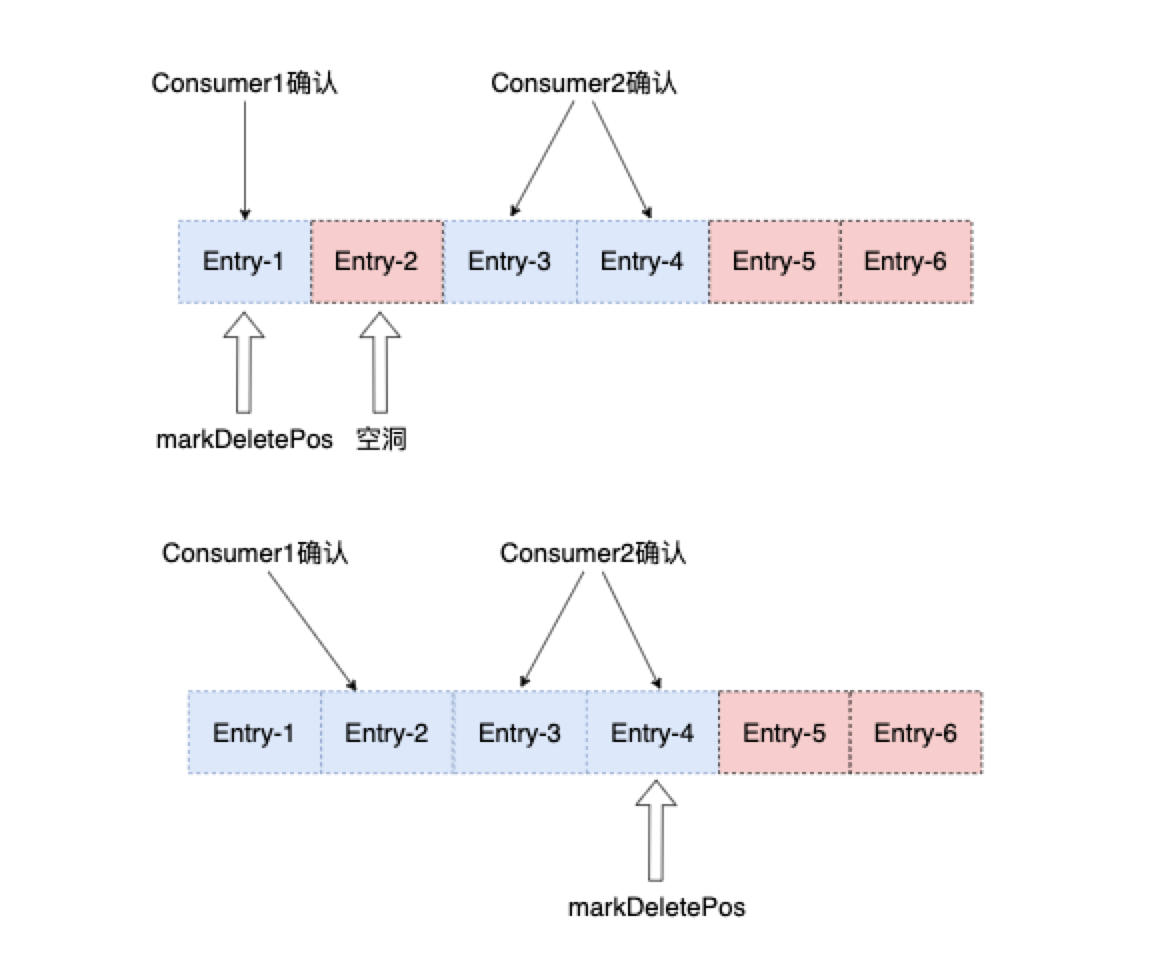
6、支持消息空洞,处理并发消费模式更加便捷;
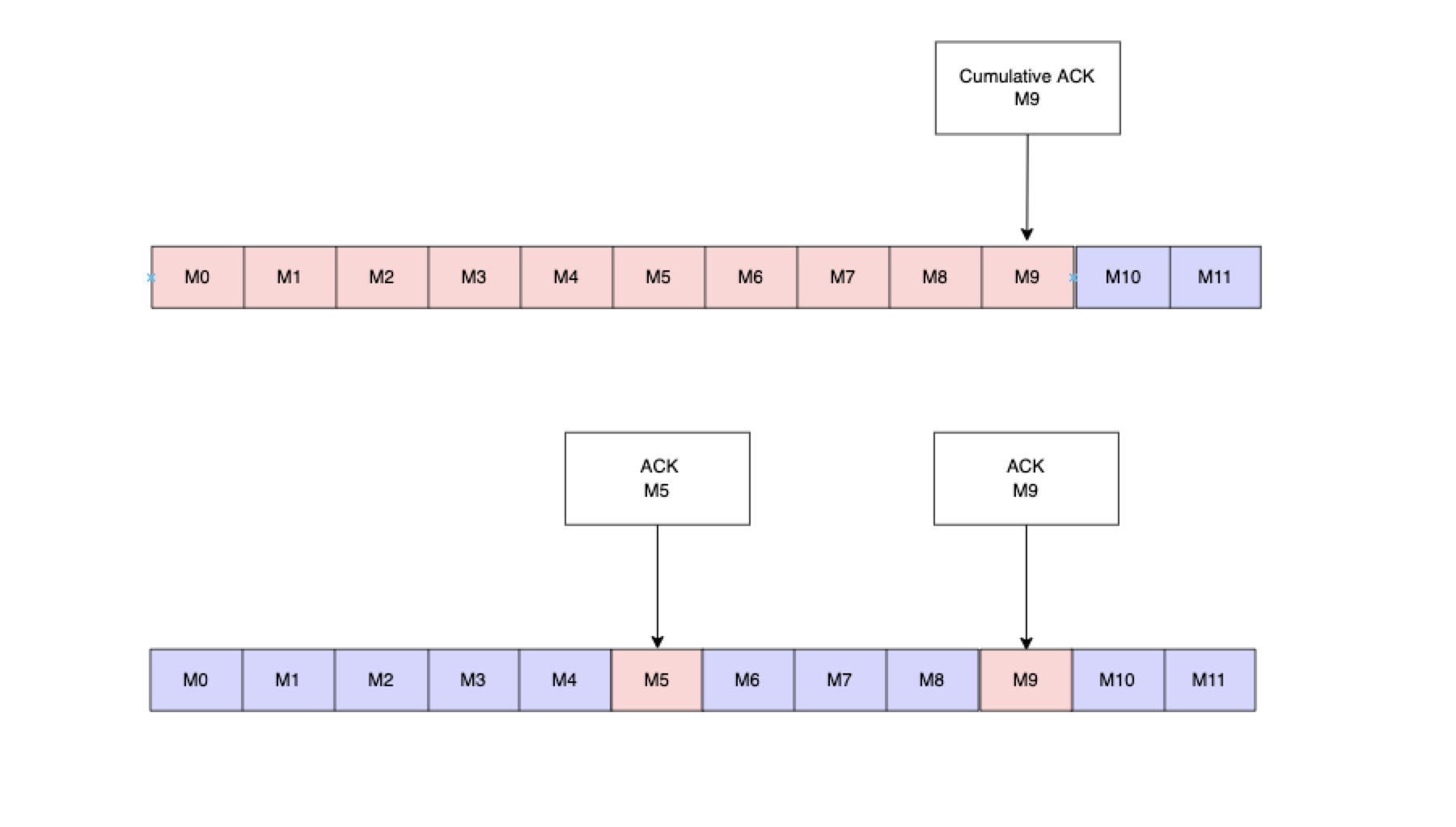
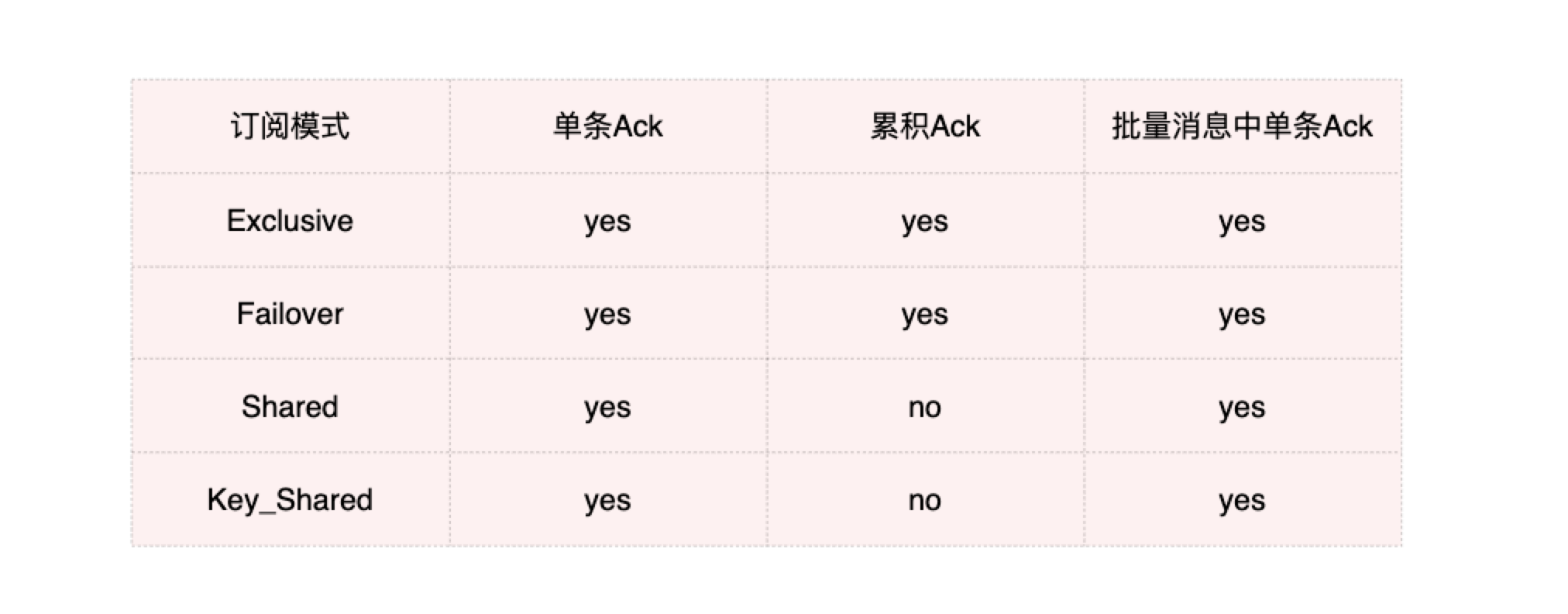
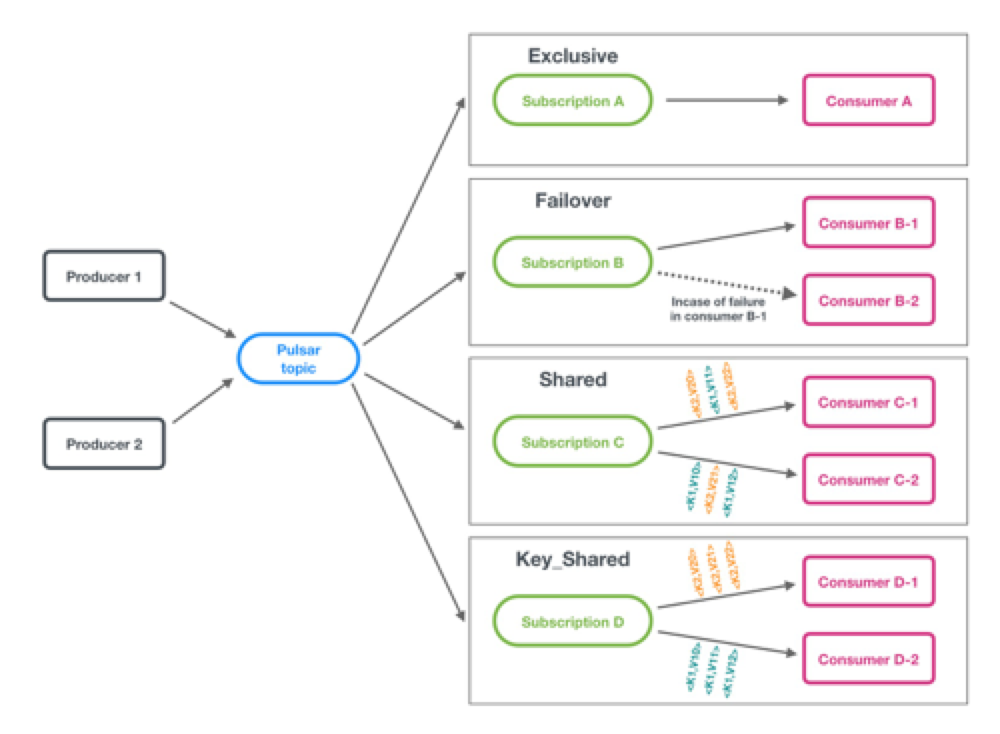
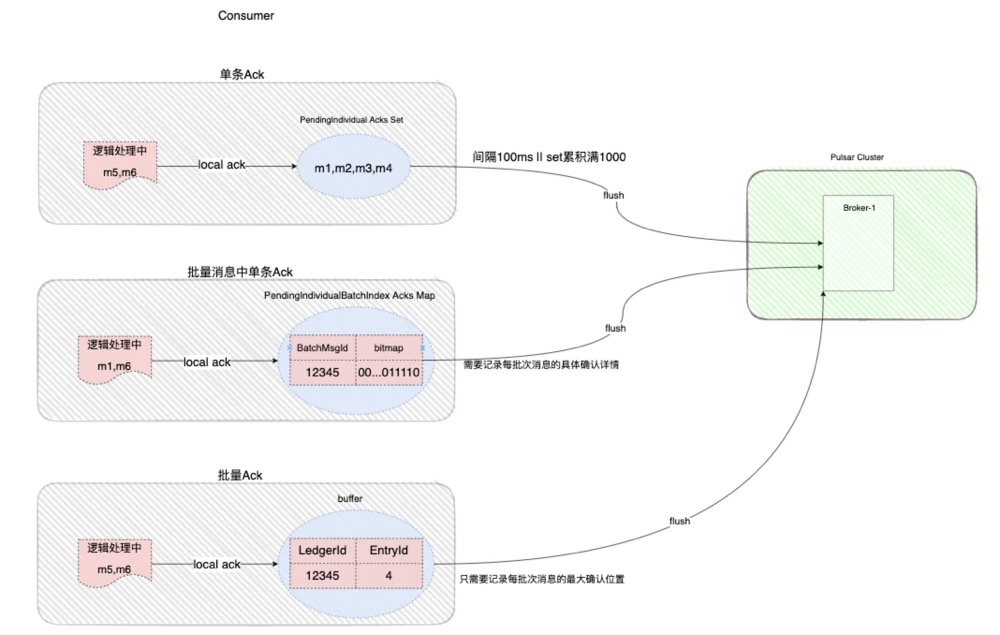
先来回顾一下上文中的两个核心概念 :订阅模式 与 Ack模式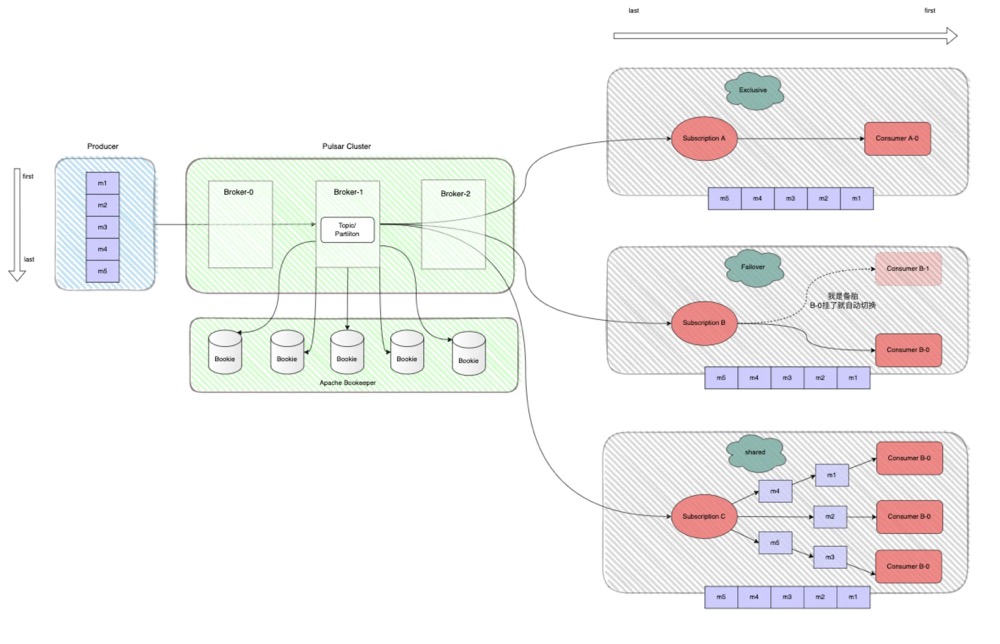
–
接下来对每一种模式进行细说:
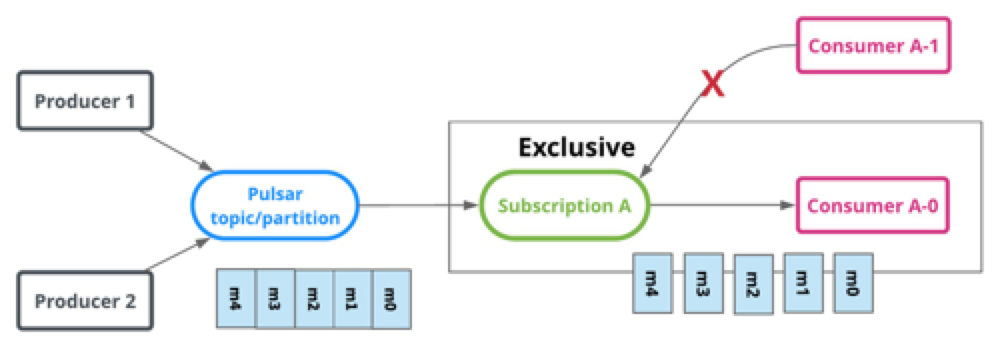
第一种 - 独占模式(Exclusive)
一个 Subscription 只能与一个 Consumer 关联,只有这个 Consumer 可以接收到 Topic 的全部消息,如果该 Consumer 出现故障了就会停止消费。
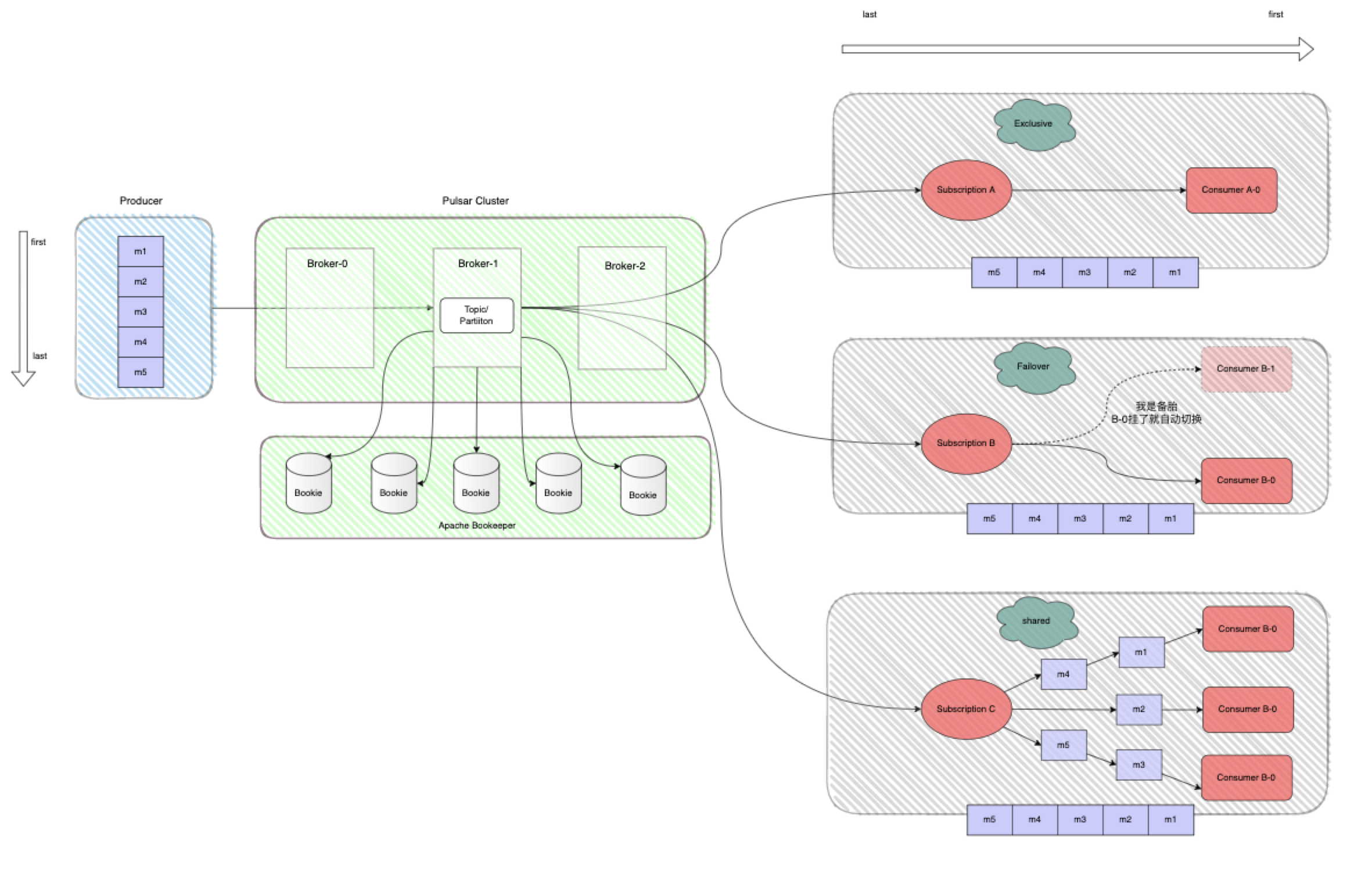
Exclusive 订阅模式下,同一个 Subscription 里只有一个 Consumer 能消费 Topic,如果多个 Consumer 订阅则会报错,,也就是说一个消费者处理主题的所有分区,适用于全局有序且对性能要求不高的消费场景,如下图所示: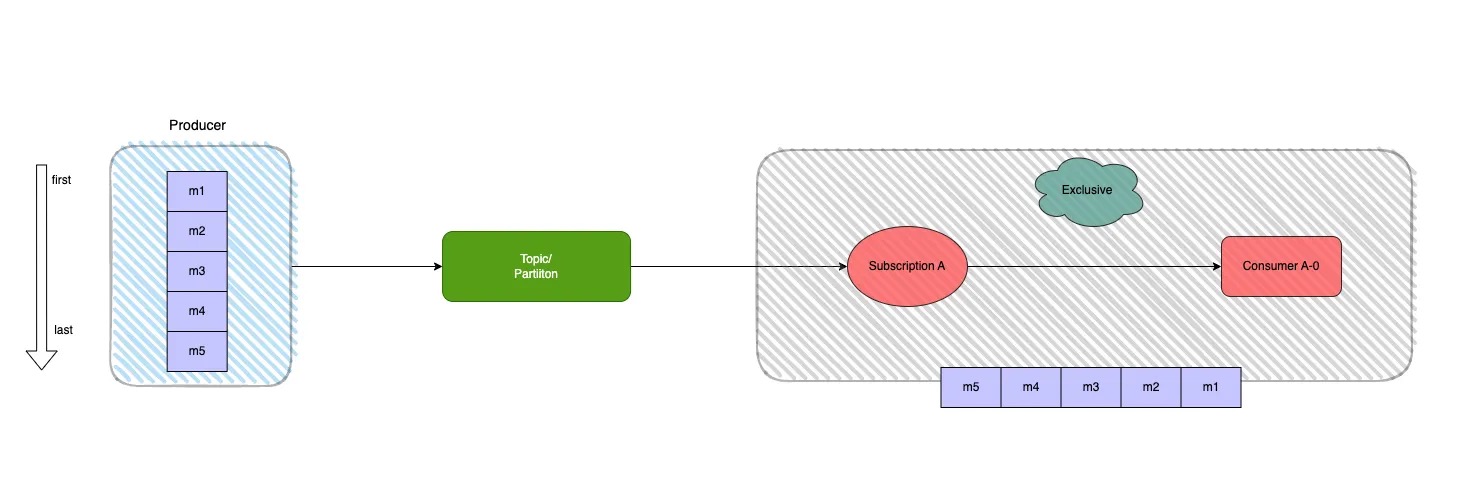
这个是Consumer B启动时会报错,只有ConsumerA能收到消息。
注意:Pulsar默认的订阅类型为 Exclusive。
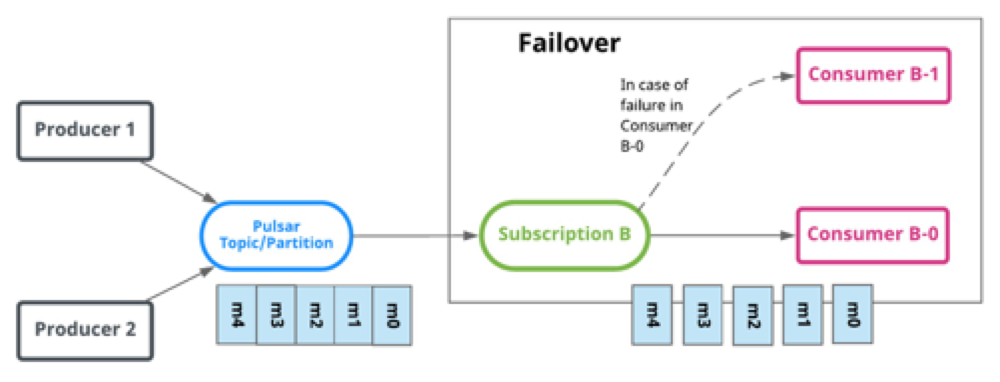
第二种 - 灾备模式(Failover)
当存在多个 consumer 时,将会按字典顺序排序,第一个 consumer 被初始化为唯一接受消息的消费者。当第一个 consumer 断开时,所有的消息(未被确认和后续进入的)将会被分发给队列中的下一个 consumer。说到这里其实会有一个误区,常常会认为该模式是上述Exclusive模式上增加了一个backup机制,其实不然,这两个模式并无任何关联,请听分解:
Failover订阅模式,可以允许多个消费者附加到一个订阅上。消费者的队列分配策略根据主题类型有所区别:
如果是分区主题(一个主题拥有多个队列的主题),Broker服务端会根据消费者优先级和消费者名称字典顺序进行排序,然后Broker会将主题中的分区平均分配给高优先级的消费者,低优先级消费者会成为分区的备消费者。
如果是非分区主题,Broker按照消费者订阅主题的顺序选择主消费者,其他的成为备消费者。
非分区主题的订阅示例说明如下: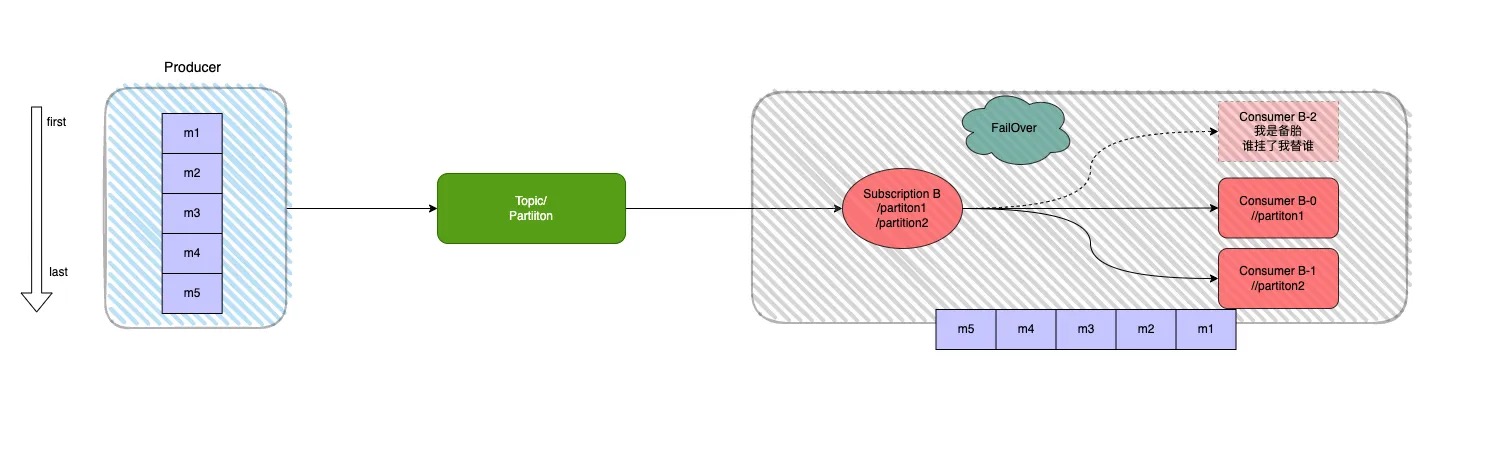
对于分区主题的订阅图解说明如下:

所以你能看到这种消费模式接近于kafka的消费模式,并且有了backup机制,并且还没有rebalance!为什么没有rebalance?因为无状态broker端做了hash映射,已推送但是没有ack数据按原hash方式,新来数据按新hash方式;
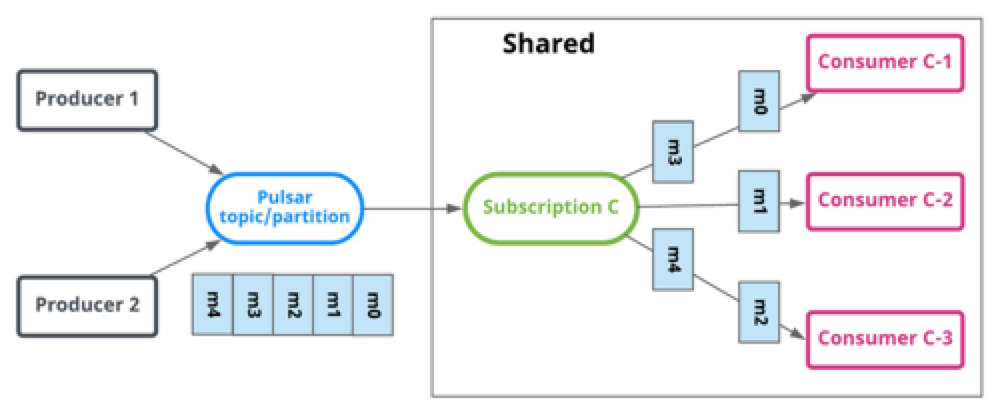
第三种 - 共享模式(Shared)
消息通过 round robin 轮询机制(也可以自定义)分发给不同的消费者,并且每个消息仅会被分发给一个消费者。当消费者断开连接,所有被发送给他,但没有被确认的消息将被重新安排,分发给其它存活的消费者。
在Shared订阅模式下,多个消费者可以附加到同一个订阅,消息以循环分发的方式轮流发送给各个消费者,并且任何给定的消息只会传递给一个消费者,当一个消费者断开连接时,所有发送给它并未被确认的消息将重新调度,再发送给其他消费者。
Shared模式的订阅图解如下所示:

上图中的ConsumerA、ConsumerB、ConsumerC都会参与消息消费。
Shared模式与Failover模式的主要差别是Shared模式并不和消费者绑定队列,即Shared模式将所有分区的消息当成一个整体来看,
使用Shared模式需要的几个注意事项:
无法保证消息的顺序性
Shared模式不能使用累积确认机制。
这种模式的最大缺点是不能启用累积确认机制,消息确认效率会降低,但其优势也比较明显,在解决单个队列积压方面,能充分所有消费者的处理能力。我们的VDC引擎调度就是按照该模式构建一个支持优先级的调度中心。
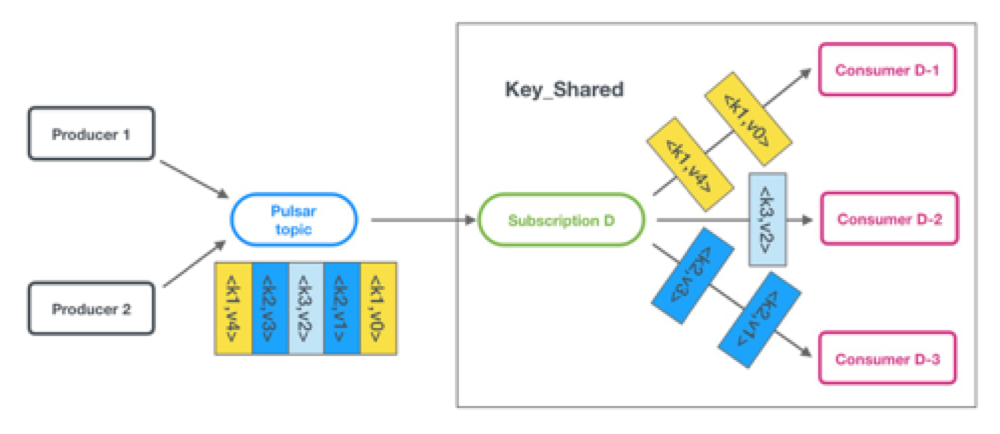
第四种 - KEY 共享模式(Key_Shared)
在Key_Shared模式中,多个消费者可以附加到同一个订阅。具有相同Key的消息会分发给同一个消费者。
Key_Shared模式的消息分发机制如下所示:

Pulsar提供了Sticky(粘性)、Auto-split Hash Range(自动分割哈希范围)、Auto-split Consistent Hashing(自动分割一致性哈希)这三种选择算法。
选择消费者的基本过程如下所示:
将分片Key传递到一个哈希函数,生成一个哈希值
将Key的哈希值传入到对应的分片算法中,从而选择出一个消费者。
注意:
Key_Shared 本身在使用上存在一定的限制条件,由于其工程实现复杂度较高,在社区版本迭代中,不断有对 Key_Shared 的功能进行改进以及优化,整体稳定性相较 Exclusive,Failover 和 Shared 这三种订阅类型偏弱。如果上述三种订阅类型能满足业务需要,可以优先选用上述三种订阅类型。
专业集群可以保证相同 KEY 的消息按顺序投递;虚拟集群无法保障消息投递顺序。
当一个新的消费者加入或者一个消费者退出时,分配算法都将会重新计算消息到消费者的映射(选择)。
接下来分别介绍这三种分配算法底层的工作机制。
订阅模式如何选择
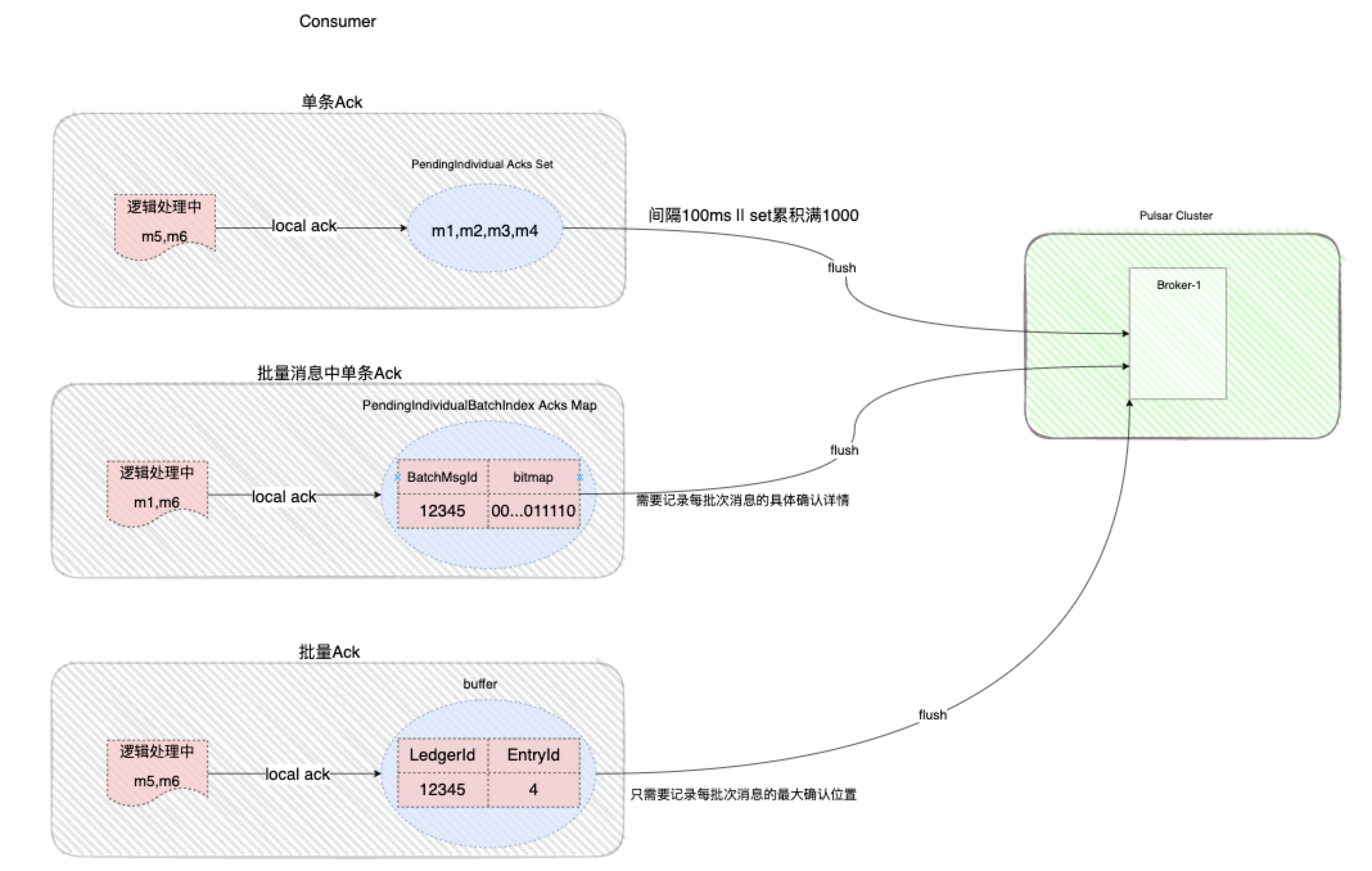
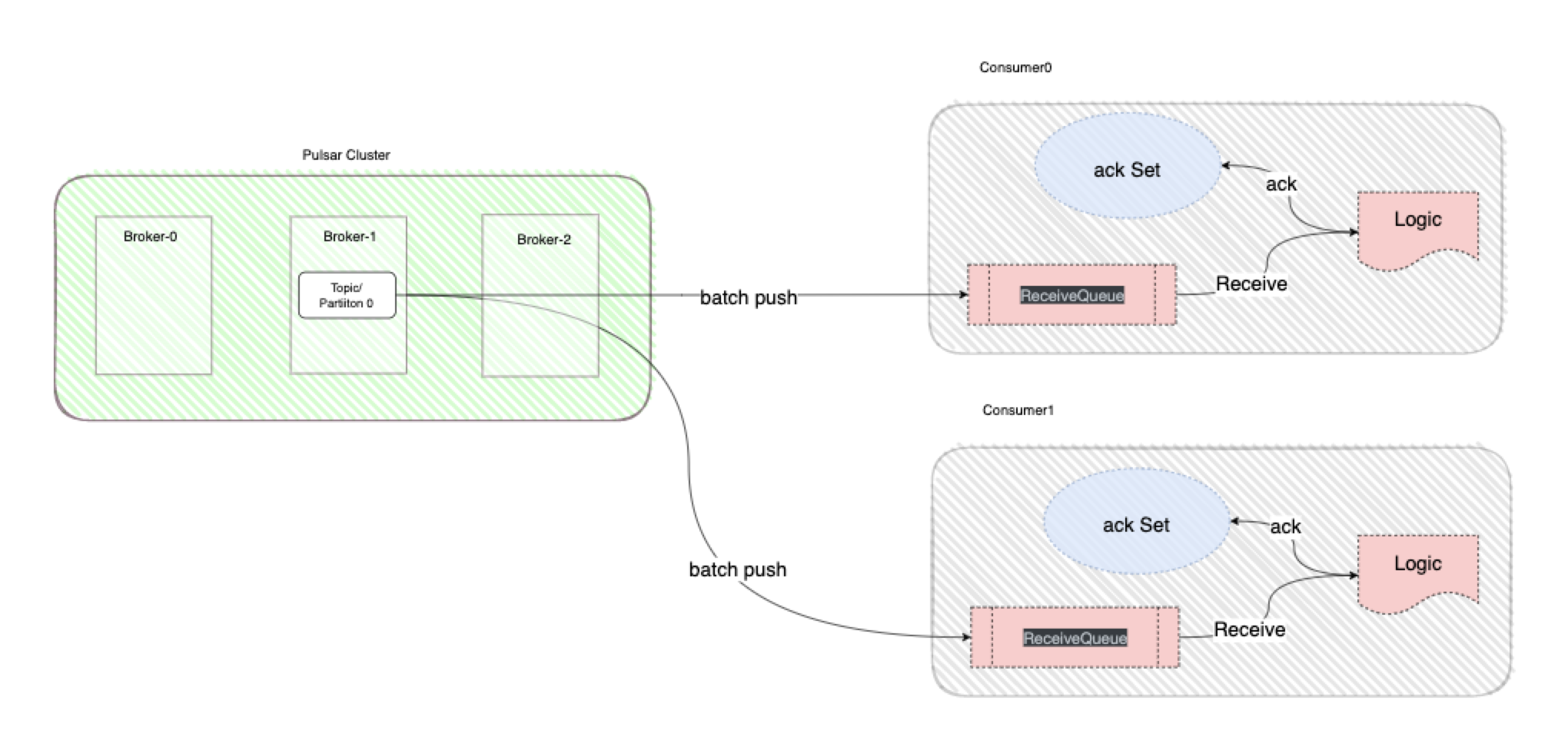
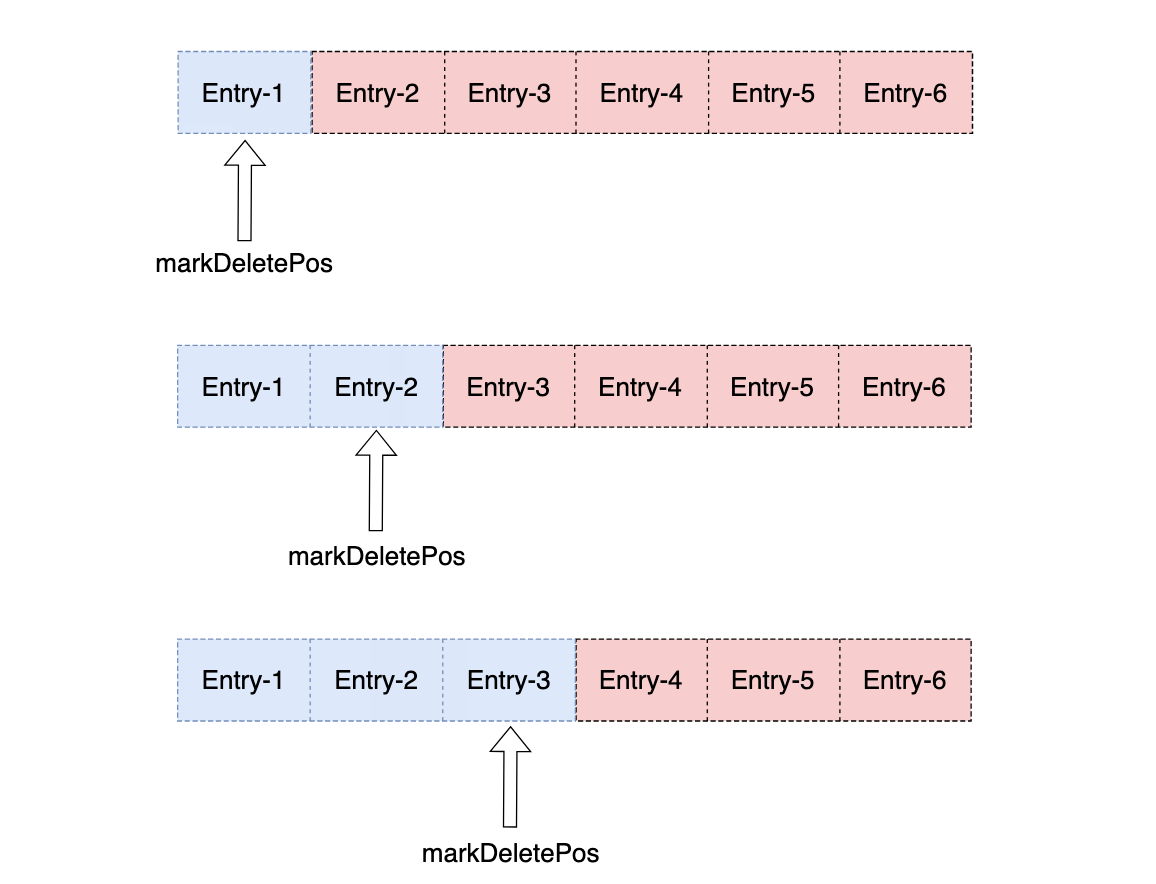
平时的工作当中,一般正常情况下选择Shared模式即可,每一个Consumer都会消费同一个Partition中的数据,每一条消息只会发送给一个Consumer,例如VDC的调度数据消费就是采用的这种模式,这种模式下消息是无序的,Consumer可以利用协程池进行消息的并发出,然后对批量消息进行单条数据的进行Ack即可,因为Broker上的Cursor会记录每一个consumer在该partition上的消费进度以及消息空洞信息,对失败数据会进行重发;
如果需要让相同 Key 的消息分给同一个消费者,或者说是需要保证消息的顺序性,这个时候 Shared 订阅模式无法满足需求了。有两种方式可供选择:Key_Shared订阅模式 或者 通过多分区主题 + Failover 订阅模式实现,如果同时满足Key 数量多且每个 Key 的消息分布相对均匀并且消费处理速度快,无消息堆积两种条件,那么就推荐使用Key_shared模式,如果上述两个条件一个不满足,则推荐使用【多分区主题 + Failover 订阅】
如果对顺序要求严格并且对性能要求不高,也可以选用Exclusive模式, 在这种模式下需要定期对服务做好严格的健康检查;